- 1 tõese või
- 0 vale korral
Logistilise regressiooni peamine tähtsus:
- Sõltumatud muutujad ei tohi olla multikollineaarsused; kui on mingi suhe, siis peaks see olema väga väike.
- Paremate tulemuste saamiseks peaks logistilise regressiooni andmekogum olema piisavalt suur.
- Ainult need atribuudid peaksid olema andmekogumis, millel on mingi tähendus.
- Sõltumatud muutujad peavad olema vastavalt palgikoefitsiendid.
Et ehitada mudel logistiline regressioon, me kasutame scikit-õppida raamatukogu. Logistilise regressiooni protsess pythonis on toodud allpool:
- Importige kõik logistilise regressiooni ja muude teekide jaoks vajalikud paketid.
- Laadige üles andmekogum.
- Mõista sõltumatuid andmekogumi muutujaid ja sõltuvaid muutujaid.
- Jagage andmekogum koolitus- ja testandmeteks.
- Initsialiseeri logistiline regressioonimudel.
- Sobitage mudel treeningu andmekogumiga.
- Ennustage mudel, kasutades katseandmeid, ja arvutage mudeli täpsus.
Probleem: Esimesed sammud on koguda andmekogum, millele soovime rakendada Logistiline regressioon. Andmekogum, mida siin kasutama hakkame, on MS-i andmekogumi jaoks. Selles andmekogumis on neli muutujat, millest kolm on sõltumatud muutujad (GRE, GPA, töökogemus) ja üks on sõltuv muutuja (lubatud). See andmekogum ütleb, kas kandidaat saab oma GPA, GRE või work_experience põhjal vastuvõtu mainekasse ülikooli või mitte.
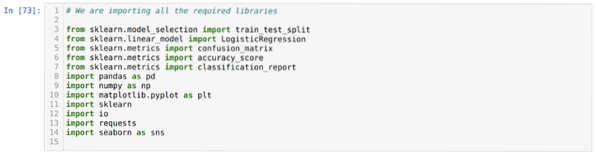
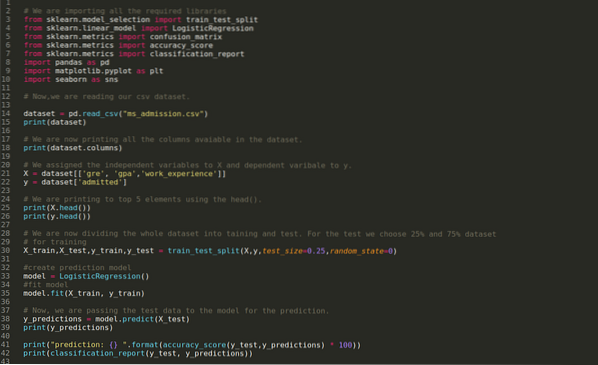
Samm 1: Impordime kõik nõutavad teegid, mida vajasime pythoni programmi jaoks.
2. samm: Nüüd laadime oma ms sissepääsu andmekogumi funktsiooni read_csv pandas abil.

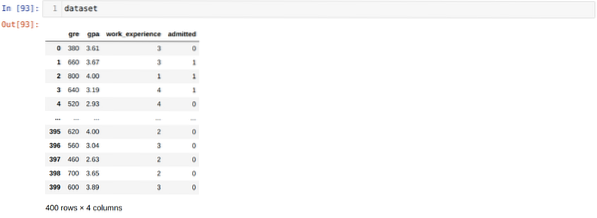
3. samm: Andmekogum näeb välja järgmine:
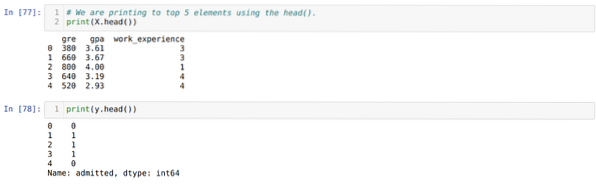
4. samm: Kontrollime kõiki andmekogumis saadaolevaid veerge ja määrame seejärel kõik sõltumatud muutujad muutujaks X ja sõltuvad muutujad väärtuseks y, nagu on näidatud alloleval ekraanipildil.

5. samm: Pärast sõltumatute muutujate X ja sõltuva muutuja y määramist printime nüüd X ja y ristkontrollimiseks peapanda funktsiooni abil.
6. samm: Nüüd jagame kogu andmekogumi koolitusteks ja testideks. Selleks kasutame sklearn'i meetodit train_test_split. Oleme andnud 25% kogu andmekogumist testile ja ülejäänud 75% andmekogumist koolitusele.
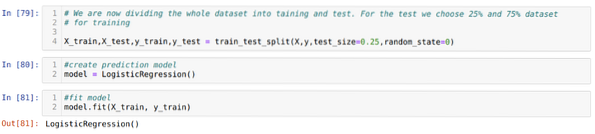
7. samm: Nüüd jagame kogu andmekogumi koolitusteks ja testideks. Selleks kasutame sklearn'i meetodit train_test_split. Oleme andnud 25% kogu andmekogumist testile ja ülejäänud 75% andmekogumist koolitusele.
Seejärel loome logistilise regressiooni mudeli ja sobitame treeningu andmed.
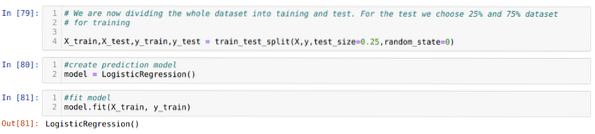
8. samm: Nüüd on meie mudel prognoosimiseks valmis, seega edastame testi (X_test) andmed mudelile ja saime tulemused. Tulemused näitavad (y_prognoosid), et väärtused 1 (lubatud) ja 0 (lubamata).

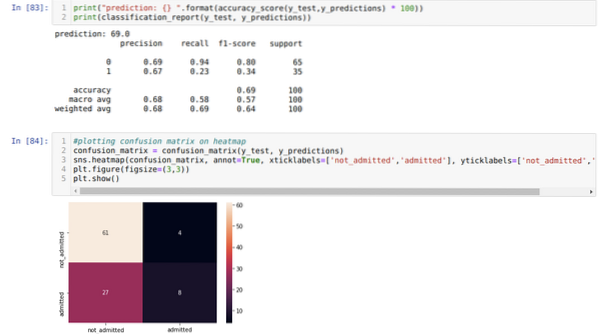
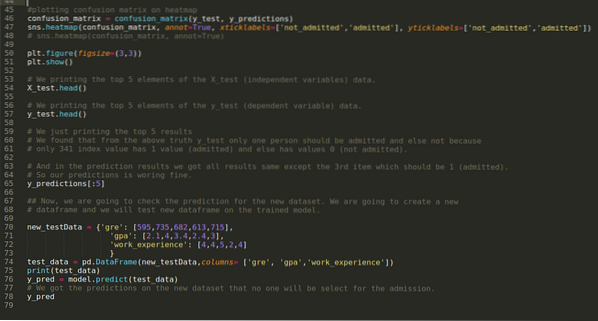
9. samm: Nüüd printime klassifitseerimisaruande ja segiajamise maatriksi.
Klassifikatsiooni_aruanne näitab, et mudel suudab tulemusi prognoosida 69% täpsusega.
Segiajamise maatriks näitab X_testi andmete üksikasju järgmiselt:
TP = tõelised positiivsed = 8
TN = tõelised negatiivsed = 61
FP = valepositiivsed = 4
FN = valenegatiivid = 27
Niisiis, kogu täpsus vastavalt confusion_matrix on:
Täpsus = (TP + TN) / kokku = (8 + 61) / 100 = 0.69
10. samm: Nüüd kontrollime tulemust printimise kaudu. Niisiis, printime lihtsalt peapandade funktsiooni X_test ja y_test (tegelik tegelik väärtus) 5 peamist elementi. Seejärel printime ka prognooside 5 parimat tulemust, nagu allpool näidatud:
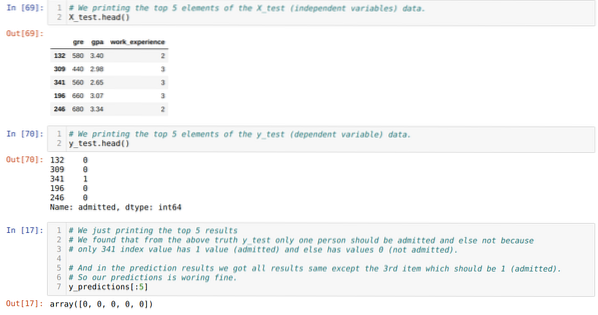
Allpool toodud prognooside mõistmiseks ühendame kõik kolm tulemust lehte. Näeme, et välja arvatud 341 X_test andmed, mis olid tõesed (1), on ennustus vale (0). Niisiis, meie mudeli ennustused töötavad 69%, nagu me juba eespool näitasime.

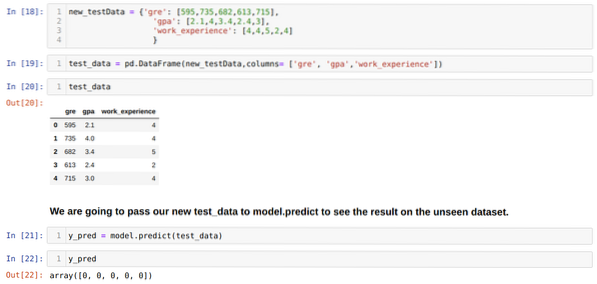
11. samm: Niisiis saame aru, kuidas tehakse mudeli ennustusi nähtamatus andmestikus nagu X_test. Niisiis lõime lihtsalt juhuslikult uue andmekogumi, kasutades pandas-andmekraami, andsime selle väljaõppinud mudelile ja saime allpool näidatud tulemuse.
Allpool esitatud täielik pythoni kood:
Selle ajaveebi kood koos andmekogumiga on saadaval järgmisel lingil
https: // github.com / shekharpandey89 / logistic-regression


