20 awk näidet
Linuxi operatsioonisüsteemis on palju kasulikke tööriistu tekstiandmetest või failist otsimiseks ja aruande loomiseks. Kasutaja saab käskude awk, grep ja sed abil hõlpsalt teha mitut tüüpi otsinguid, asendada ja aruandluse genereerimise ülesandeid. awk pole lihtsalt käsk. See on skriptikeel, mida saab kasutada nii terminali- kui ka awk-failist. See toetab muutujat, tingimuslauset, massiivi, tsükleid jne. nagu muud skriptikeeled. See suudab lugeda failide sisu rea kaupa ja eraldada väljad või veerud konkreetse eraldaja alusel. Samuti toetab see regulaaravaldist konkreetse stringi otsimiseks teksti sisus või failis ja võtab vaste leidmisel toiminguid. Kuidas saate awk-käsku ja skripti kasutada, on selles õpetuses näidatud 20 kasuliku näite abil.
Sisu:
- awk printf-ga
- awk jaguneb valgele ruumile
- piiraja muutmiseks awk
- awk sakkidega eraldatud andmetega
- awk koos csv-andmetega
- awk regex
- awk case tundetu regex
- awk muutujaga nf (väljade arv)
- awk gensub () funktsioon
- awk koos rand () funktsiooniga
- awk kasutaja määratletud funktsioon
- awk kui
- awk muutujad
- awk massiivid
- awk silmus
- esimese veeru printimiseks awk
- viimase veeru printimiseks awk
- awk koos grepiga
- awk koos bashi skriptifailiga
- awk koos sed
Awk kasutamine printf-iga
printf () Funktsiooni kasutatakse mis tahes väljundi vormindamiseks enamikus programmeerimiskeeltes. Seda funktsiooni saab kasutada koos awk käsk erinevat tüüpi vormindatud väljundite genereerimiseks. awk-käsk, mida kasutatakse peamiselt mis tahes tekstifailide jaoks. Looge nimega tekstifail töötaja.txt allpool toodud sisuga, kus väljad on eraldatud vahekaardiga ('\ t').
töötaja.txt
1001 John sena 400001002 Jafar Iqbal 60000
1003 Meher Nigar 30000
1004 Jonny Maks 70000
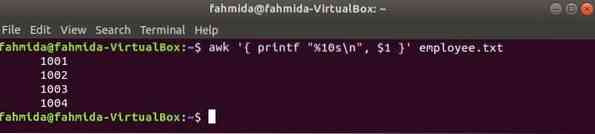
Järgmine käsk awk loeb andmeid asukohast töötaja.txt fail rea kaupa ja printige esimene fail pärast vormindamist. Siin,% 10s \ n”Tähendab, et väljund on 10 tähemärki pikk. Kui väljundi väärtus on väiksem kui 10 tähemärki, lisatakse väärtuse ette tühikud.
$ awk 'printf "% 10s \ n", $ 1' töötaja.txtVäljund:
Avage sisu
awk jaguneb valgele ruumile
Vaikimisi sõna või välja eraldaja mis tahes teksti jagamiseks on tühik. käsk awk võib teksti väärtust sisestada mitmel viisil. Sisestatud tekst edastatakse kaja käsk järgmises näites. Tekst, "Mulle meeldib programmeerida'jagatakse vaikimisi eraldajana, ruumi, ja kolmas sõna trükitakse väljundina.
$ kaja 'Mulle meeldib programmeerimine' | awk 'print $ 3'Väljund:

Avage sisu
piiraja muutmiseks awk
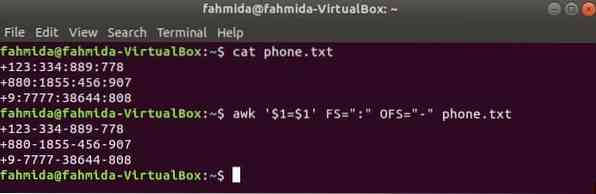
käsku awk saab kasutada mis tahes failisisu eraldaja muutmiseks. Oletame, et teil on tekstifail nimega telefon.txt järgmise sisuga, kus faili sisu väljaeraldajana kasutatakse ':'.
telefon.txt
+123: 334: 889: 778+880: 1855: 456: 907
+9: 7777: 38644: 808
Piiraja muutmiseks käivitage järgmine käsk awk, ":" kõrval '-' faili sisule, telefon.txt.
$ kass telefon.txt$ awk '$ 1 = $ 1' FS = ":" OFS = "-" telefon.txt
Väljund:
Avage sisu
awk sakkidega eraldatud andmetega
käsul awk on palju sisseehitatud muutujaid, mida kasutatakse teksti erineval viisil lugemiseks. Kaks neist on FS ja OFS. FS on sisendvälja eraldaja ja OFS on väljundvälja eraldaja muutujad. Nende muutujate kasutusalad on toodud selles jaotises. Loo vaheleht eraldatud fail nimega sisend.txt järgmise sisuga, et testida FS ja OFS muutujad.
Sisend.txt
Kliendipoolne skriptikeelServeripoolne skriptikeel
Andmebaasiserver
Veebiserver
Muutuja FS kasutamine vahekaardiga
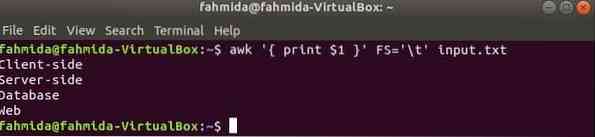
Järgmine käsk jagab iga rea sisend.txt faili vahelehe põhjal ('\ t') ja printige iga rea esimene väli.
$ awk 'print $ 1' FS = '\ t' sisend.txtVäljund:
Muutuja OFS kasutamine vahekaardiga
Järgmine awk käsk prindib 9th ja 5th väljad 'ls -l' pärast veeru pealkirja printimist vahekaardi eraldajaga käskNimi"Ja"Suurus”. Siin, OFS muutujat kasutatakse väljundi vahelehe vormindamiseks.
$ ls -l$ ls -l | awk -v OFS = '\ t' 'BEGIN printf "% s \ t% s \ n", "nimi", "suurus" print $ 9, $ 5'
Väljund:

Avage sisu
awk CSV-andmetega
Mis tahes CSV-faili sisu saab parsida käsuga awk mitmel viisil. Looge CSV-fail nimega 'klient.csv'Järgmise sisuga käsu awk rakendamiseks.
klient.txt
Id, nimi, e-posti aadress, telefon1, Sophia, [meiliga kaitstud], (862) 478-7263
2, Amelia, [meiliga kaitstud], (530) 764-8000
3, Emma, [meiliga kaitstud], (542) 986-2390
CSV-faili ühe välja lugemine
"-F" Valikut kasutatakse käsuga awk, et määrata eraldaja faili iga rea jagamiseks. Järgmine awk käsk prindib nimi valdkonnas klient.csv faili.
$ kassi klient.csv$ awk -F "," 'print $ 2' klient.csv
Väljund: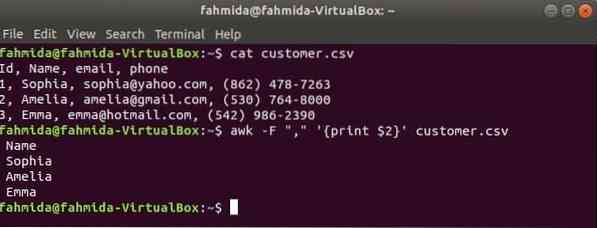
Mitme välja lugemine, kombineerides seda muu tekstiga
Järgmine käsk prindib kolm välja klient.csv pealkirja teksti kombineerimisega, Nimi, e-post ja telefon. Esimene rida klient.csv fail sisaldab iga välja pealkirja. NR muutuja sisaldab faili rea numbrit, kui käsk awk parsib faili. Selles näites, NR muutujat kasutatakse faili esimese rea väljajätmiseks. Väljund näitab 2nd, 3rd ja 4th kõigi ridade väljad, välja arvatud esimene rida.
$ awk -F "," 'NR> 1 print "Nimi:" $ 2 ", E-post:" $ 3 ", Telefon:" $ 4' klient.csvVäljund:
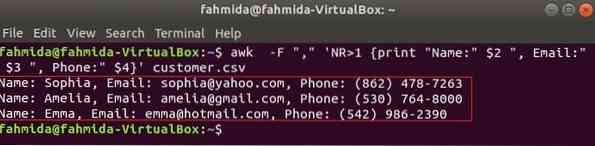
CSV-faili lugemine awk-skripti abil
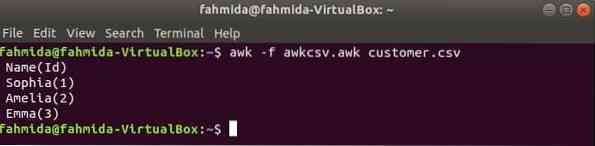
awk-skripti saab käivitada käivitades awk-faili. Kuidas saate awk-faili luua ja faili käivitada, on näidatud selles näites. Looge fail nimega awkcsv.awk järgmise koodiga. Alusta märksõna kasutatakse skriptis awk-käsu teavitamiseks, et käivitada skript Alusta osa enne teiste ülesannete täitmist. Siin on eraldaja (FS) kasutatakse jagaja eraldaja määramiseks ja 2nd ja 1st väljad prinditakse vastavalt funktsioonile printf () kasutatud vormingule.
awkcsv.awkBEGIN FS = "," printf "% 5s (% s) \ n", $ 2, $ 1
Jookse awkcsv.awk fail sisuga klient.csv faili järgmise käsuga.
$ awk -f awkcsv.awk klient.csvVäljund:
Avage sisu
awk regex
Regulaaravaldus on muster, mida kasutatakse teksti mis tahes stringi otsimiseks. Regulaaravaldist kasutades saab erinevat tüüpi keerukaid otsingu- ja asendusülesandeid väga lihtsalt teha. Selles jaotises on toodud mõned awk-käskudega regulaaravaldise lihtsad kasutusalad.
Sobiv tähemärkJärgmine käsk sobib sõnaga Loll või loll või Lahe sisestusstringiga ja printige, kui sõna leitakse. Siin, Nukk ei sobi ja ei prindi.
$ printf "Fool \ nCool \ nDoll \ nbool" | awk '/ [FbC] ool /'Väljund:

Stringi otsimine rea alguses
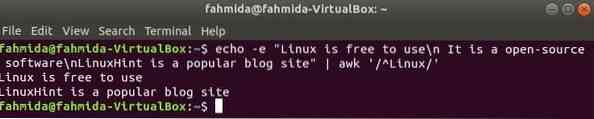
'^' sümbolit kasutatakse regulaaravaldises mis tahes mustri otsimiseks rea alguses. "Linux ' sõna otsitakse järgmise näite iga teksti rea alguses. Siin algavad kaks rida tekstiga, 'Linux"ja need kaks rida kuvatakse väljundis.
$ echo -e "Linuxit on tasuta kasutada \ n See on avatud lähtekoodiga tarkvara \ nLinuxHint onpopulaarne ajaveebisait "| awk '/ ^ Linux /'
Väljund:
Stringi otsimine rea lõpus
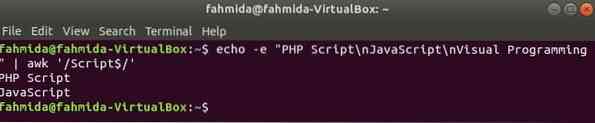
'$' sümbolit kasutatakse regulaaravaldises mis tahes mustri otsimiseks teksti iga rea lõpus. "Skriptsõna otsitakse järgmises näites. Siin sisaldab sõna kaks rida, Skript rea lõpus.
$ echo -e "PHP skript \ nJavaScript \ nVisuaalne programmeerimine" | awk '/ skript $ /'Väljund:
Otsimine konkreetse märgistiku välja jätmisega
'^' sümbol tähistab teksti algust, kui seda kasutatakse mis tahes stringimustri ees ('/ ^… /') või enne mis tahes märgistikku, mille deklareerib ^ […]. Kui '^' sümbolit kasutatakse kolmanda sulgudes, [^…], siis sulgudes määratletud märgistik jäetakse otsingu ajal tegemata. Järgmine käsk otsib kõiki sõnu, mis ei alga "F" kuid lõpeb 'ool". Lahe ja bool prinditakse vastavalt mustrile ja tekstiandmetele.
$ printf "Fool \ nCool \ nDoll \ nbool" | awk '/ [^ F] ool /'Väljund:

Avage sisu
awk case tundetu regex
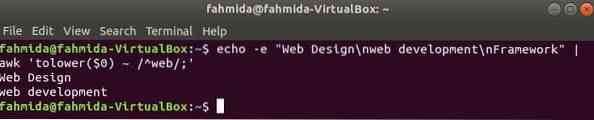
Vaikimisi teeb regulaaravaldis stringi mis tahes mustri otsimisel väiketähti. Suur- ja väiketähtede otsimist saab teha käsuga awk regulaaravaldisega. Järgmises näites, taluma () funktsiooni kasutatakse juhtumitundetu otsingu tegemiseks. Siin teisendatakse sisendteksti iga rea esimene sõna väiketähtede abil taluma () funktsiooni ja sobitada regulaaravaldise mustriga. pealmine () Funktsiooni saab kasutada ka selleks otstarbeks, sel juhul tuleb muster määratleda kogu suurtähega. Järgmises näites määratletud tekst sisaldab otsitavat sõna, 'võrk'kahel real, mis trükitakse väljundina.
$ echo -e "Veebikujundus \ nveebiarendus \ nRaam" | awk 'tolower ($ 0) ~ / ^ web /;'Väljund:
Avage sisu
awk muutujaga NF (väljade arv)
NF on käsu awk sisseehitatud muutuja, mida kasutatakse väljade koguarvude lugemiseks sisendteksti igal real. Looge mis tahes tekstifail, millel on mitu rida ja mitu sõna. sisend.txt siin kasutatakse faili, mis on loodud eelmises näites.
NF-i kasutamine käsurealt
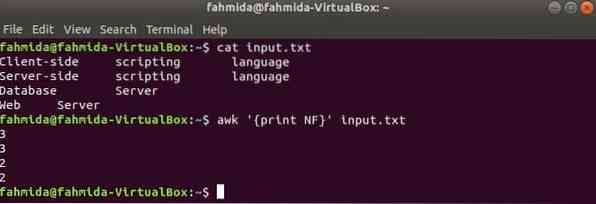
Siin kasutatakse esimest käsku sisu kuvamiseks sisend.txt faili ja teist käsku kasutatakse failide igal real olevate väljade koguarvu kuvamiseks NF muutuv.
$ cat sisend.txt$ awk 'print NF' sisend.txt
Väljund:
NF-i kasutamine awk-failis
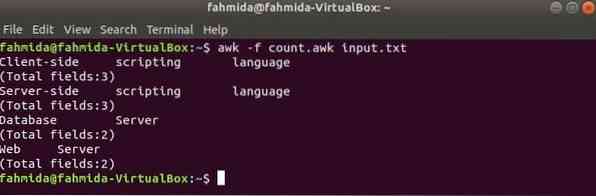
Looge awk-nimeline fail loendama.awk allpool toodud skriptiga. Kui see skript käivitatakse mis tahes tekstiandmetega, prinditakse iga rea sisu koos kõigi väljadega väljundina.
loendama.awk
print $ 0print "[Väljade koguarv:" NF "]"
Käivitage skript järgmise käsuga.
$ awk -f arv.awk sisend.txtVäljund:
Avage sisu
awk gensub () funktsioon
saabub () on asendusfunktsioon, mida kasutatakse stringi otsimiseks kindla eraldaja või regulaaravaldise mustri põhjal. See funktsioon on määratletud jaotises "gawk" pakett, mis pole vaikimisi installitud. Selle funktsiooni süntaks on toodud allpool. Esimene parameeter sisaldab regulaaravaldise mustrit või otsingu eraldajat, teine parameeter sisaldab asendusteksti, kolmas parameeter näitab, kuidas otsitakse ja viimane parameeter sisaldab teksti, milles seda funktsiooni rakendatakse.
Süntaks:
gensub (regexp, asendamine, kuidas [, target])Installimiseks käivitage järgmine käsk gawk pakett kasutamiseks saabub () funktsioon awk käsuga.
$ sudo apt-get install gawkLoo tekstifail nimega 'müügiinfo.txt"selle näite praktiseerimiseks järgmise sisuga. Siin eraldavad väljad vaheleht.
müügiinfo.txt
E 700000Teisipäev 800000
P 750000
N 200000
R 430000
Laupäev 820000
Käivitage järgmine käsk faili numbriväljade lugemiseks müügiinfo.txt fail ja printige kogu müügisumma kokku. Kolmas parameeter G tähistab siin ülemaailmset otsingut. See tähendab, et mustrit otsitakse kogu faili sisust.
$ awk 'x = gensub ("\ t", "", "G", $ 2); printf x "+" END print 0 'müügiinfo.txt | bc -lVäljund:

Avage sisu
awk koos rand () funktsiooniga
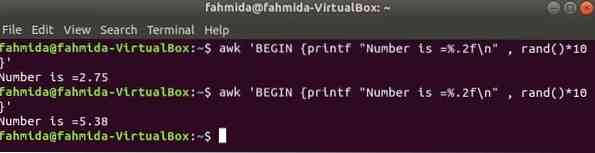
rand () Funktsiooni kasutatakse mis tahes juhusliku arvu genereerimiseks, mis on suurem kui 0 ja väiksem kui 1. Seega genereerib see alati murdarvu alla 1. Järgmine käsk genereerib murdarvu juhusliku arvu ja korrutab väärtuse 10-ga, et saada arv rohkem kui 1. Funktsiooni printf () rakendamiseks prinditakse kümnendkoha järel kahe numbriga murdarv. Kui käivitate järgmise käsu mitu korda, saate iga kord erineva väljundi.
$ awk 'BEGIN printf "Arv on =%.2f \ n ", rand () * 10 'Väljund:
Avage sisu
awk kasutaja määratletud funktsioon
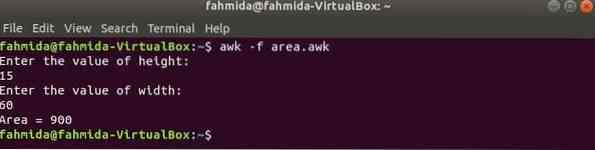
Kõik eelmistes näidetes kasutatud funktsioonid on sisseehitatud funktsioonid. Kuid saate oma awk-skriptis deklareerida kasutaja määratletud funktsiooni mis tahes konkreetse ülesande täitmiseks. Oletame, et soovite ristküliku pindala arvutamiseks luua kohandatud funktsiooni. Selle toimingu tegemiseks looge fail nimega 'piirkonnas.awk'järgmise skriptiga. Selles näites kasutaja määratud funktsioon nimega ala () deklareeritakse skriptis, mis arvutab ala sisendparameetrite põhjal ja tagastab ala väärtuse. getline käsku kasutatakse siin kasutaja sisendi võtmiseks.
piirkonnas.awk
# Arvuta pindalafunktsiooniala (kõrgus, laius)
tagasivoolu kõrgus * laius
# Alustab täitmist
BEGIN
print "Sisestage kõrguse väärtus:"
getline h < "-"
print "Sisesta laiuse väärtus:"
getline w < "-"
print "ala =" ala (h, w)
Käivitage skript.
$ awk -f ala.awkVäljund:
Avage sisu
awk kui näide
awk toetab tingimuslauseid nagu teisi standardseid programmeerimiskeeli. Kolme näidet kasutades saab selles jaotises näidata kolme tüüpi avaldusi. Looge nimega tekstifail esemed.txt järgmise sisuga.
esemed.txt
HDD Samsung 100 dollaritHiir A4Tech
Printer HP 200 dollarit
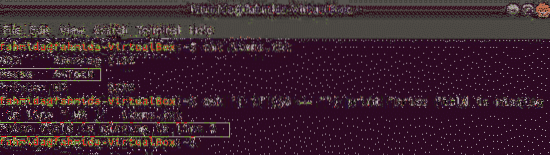
Lihtne, kui näide:
ta järgib käsku esemed.txt fail ja kontrollige 3rd välja väärtus igal real. Kui väärtus on tühi, prindib see veateate koos rea numbriga.
$ awk 'if ($ 3 == "") print "Rea" NR' üksustes puudub hinnaväli.txtVäljund:
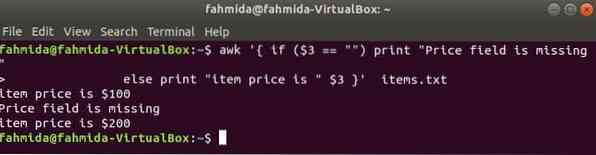
kui-muu näide:
Järgmine käsk prindib toote hinna, kui 3rd väli on real olemas, vastasel juhul prindib see tõrketeate.
$ awk 'if ($ 3 == "") print "Hinnaväli puudub"muidu print "üksuse hind on" $ 3 "üksust.txt
Väljund:
kui-muidu-kui näide:
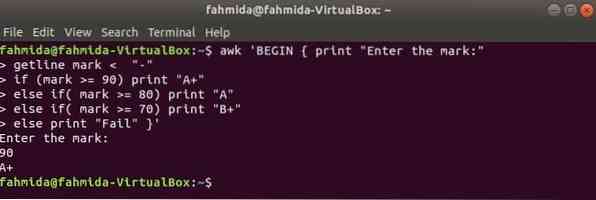
Kui järgmine käsk käivitatakse terminalist, võtab see kasutaja sisendi. Sisendväärtust võrreldakse iga tingimusega, kuni tingimus on tõene. Kui mõni tingimus saab tõeks, prindib see vastava hinde. Kui sisendväärtus ei ühti ühegi tingimusega, siis printimine ebaõnnestub.
$ awk 'BEGIN print "Sisestage märk:"getline märk < "-"
kui (märk> = 90) printige "A +"
muul juhul, kui (märk> = 80) printida "A"
else if (märk> = 70) printige "B +"
muul juhul printige "Fail" '
Väljund:
Avage sisu
awk muutujad
Muutuja awk deklaratsioon sarnaneb shellimuutuja deklaratsiooniga. Muutuja väärtuse lugemisel on erinevus. Väärtuse lugemiseks kasutatakse shellimuutuja muutuja nimega sümbolit $. Kuid väärtuse lugemiseks pole vaja kasutada muutujaga awk '$'.
Kasutades lihtsat muutujat:
Järgmine käsk kuulutab muutuja nimega 'sait' ja sellele muutujale määratakse stringi väärtus. Muutuja väärtus trükitakse järgmises lauses.
$ awk 'BEGIN site = "LinuxHint.com "; prindi sait 'Väljund:

Muutuja kasutamine failist andmete hankimiseks
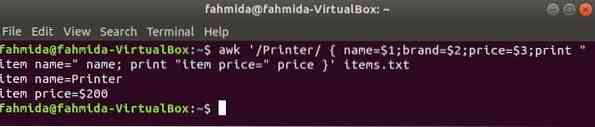
Järgmine käsk otsib sõna 'Printer' failis esemed.txt. Kui mõni faili rida algab tähega 'Printersiis salvestab see väärtuse 1st, 2nd ja 3rd väljad kolmeks muutujaks. nimi ja hind muutujad prinditakse.
$ awk '/ Printer / nimi = $ 1; bränd = 2 dollarit; hind = 3 dollarit; print "üksuse nimi =" nimi;printige "item price =" price "üksused.txt
Väljund:
Avage sisu
awk massiivid
Nii arv- kui ka seotud massiive saab kasutada awk-s. Massiivmuutuja deklaratsioon awk-s on sama mis teiste programmeerimiskeeltega. Selles jaotises on toodud mõned massiivide kasutusalad.
Assotsiatiivne massiiv:
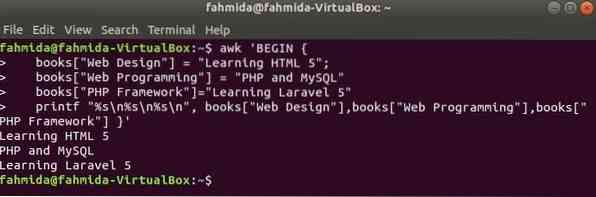
Massiivi indeks on assotsiatiivse massiivi mis tahes string. Selles näites deklareeritakse ja prinditakse kolme elemendi assotsiatiivne massiiv.
$ awk 'BEGINraamatud ["Veebikujundus"] = "HTML 5 õppimine";
raamatud ["Veebiprogrammid"] = "PHP ja MySQL"
raamatud ["PHP Framework"] = "Laravel 5 õppimine"
printf "% s \ n% s \ n% s \ n", raamatud ["Veebikujundus"], raamatud ["Veebiprogrammid"],
raamatud ["PHP raamistik"] '
Väljund:
Numbriline massiiv:
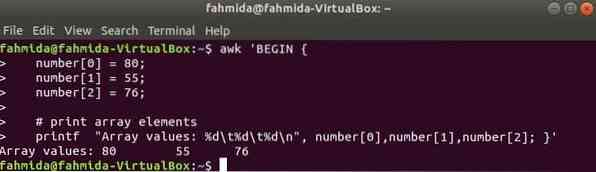
Kolme elemendi numbriline massiiv deklareeritakse ja prinditakse vahekaardiga.
$ awk 'BEGINarv [0] = 80;
arv [1] = 55;
arv [2] = 76;
# massiivi elemendi printimine
printf "Massiivi väärtused:% d \ t% d \ t% d \ n", arv [0], arv [1], arv [2]; '
Väljund:
Avage sisu
awk silmus
AWK toetab kolme tüüpi silmuseid. Nende silmuste kasutusviise on siin näidatud kolme näite abil.
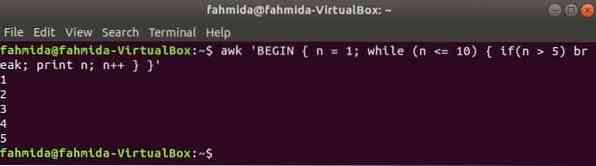
Kuigi silmus:
samas kui järgmises käsus kasutatav tsükkel kordub viis korda ja väljub katkestuse lause silmusest.
$ Awk 'ALGUS n = 1; samas (n <= 10) if(n > 5) murda; trükk n; n ++ 'Väljund:
Silmuse jaoks:
Järgmises käskus awk kasutatud silmus arvutab summa vahemikku 1 kuni 10 ja prindib väärtuse.
$ awk 'BEGIN summa = 0; jaoks (n = 1; n <= 10; n++) sum=sum+n; print sum 'Väljund:

Do-while silmus:
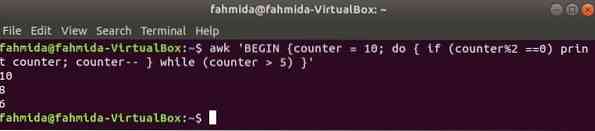
järgmise käsu tsükkel do-while prindib kõik paarisarvud vahemikus 10–5.
$ awk 'BEGIN loendur = 10; do if (loendur% 2 == 0) prindi loendur; loendur -samas (loendur> 5) '
Väljund:
Avage sisu
esimese veeru printimiseks awk
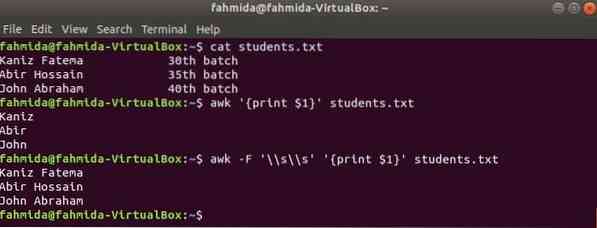
Iga faili esimese veeru saab printida, kasutades awk-s muutujat $ 1. Kuid kui esimese veeru väärtus sisaldab mitut sõna, prinditakse ainult esimese veeru esimene sõna. Spetsiifilise eraldaja abil saab esimese veeru korralikult printida. Looge nimega tekstifail õpilased.txt järgmise sisuga. Esimene veerg sisaldab siin kahe sõna teksti.
Üliõpilased.txt
Kaniz Fatema 30th partiiAbir Hossain 35th partii
Johannes Aabraham 40th partii
Käivitage käsk awk ilma eraldajata. Esimese veeru esimene osa prinditakse.
$ awk 'print $ 1' õpilased.txtKäivitage käsk awk järgmise eraldajaga. Esimese veeru täielik osa prinditakse.
$ awk -F '\\ s \\ s' 'print $ 1' õpilased.txtVäljund:
Avage sisu
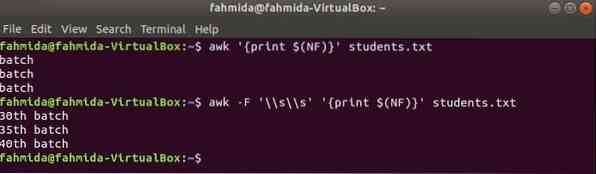
viimase veeru printimiseks awk
$ (NF) muutujat saab kasutada mis tahes faili viimase veeru printimiseks. Järgmised awk-käsud trükivad saidi viimase veeru viimase osa ja kogu osa üliõpilased.txt faili.
$ awk 'print $ (NF)' õpilased.txt$ awk -F '\\ s \\ s' 'print $ (NF)' õpilased.txt
Väljund:
Avage sisu
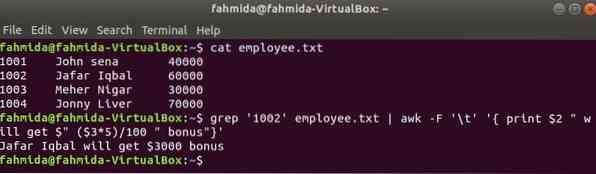
awk koos grepiga
grep on veel üks kasulik Linuxi käsk failist sisu otsimiseks mis tahes regulaaravaldise põhjal. Kuidas käske awk ja grep koos kasutada, on näidatud järgmises näites. grep käsku kasutatakse töötaja ID teabe otsimiseks. "1002'alates töötaja.txt faili. Grep-käsu väljund saadetakse sisendandmetena awk-le. 5% lisatasu arvestatakse ja trükitakse vastavalt töötaja ID palgale. "1002 ' awk käsuga.
$ kassi töötaja.txt$ grep '1002' töötaja.txt | awk -F '\ t' 'print $ 2 "saab $" ($ 3 * 5) / 100 "boonus"'
Väljund:
Avage sisu
awk failiga BASH
Nagu teistegi Linuxi käske, saab ka awk-käsku kasutada BASH-skriptis. Looge nimega tekstifail klientidele.txt järgmise sisuga. Selle faili iga rida sisaldab teavet neljal väljal. Need on kliendi ID, nimi, aadress ja mobiilinumber, mis on eraldatud "/".
klientidele.txt
AL4934 / Charles M Brunner / 4838 Beeghley tänav, Huntsville, Alabama / 256-671-7942CA5455 / Virginia S Mota / 930 Bassel Street, VALLECITO, California / 415-679-5908
IL4855 / Ann A Neale / 1932 Patterson Fork Road, Chicago, Illinois / 773-550-5107
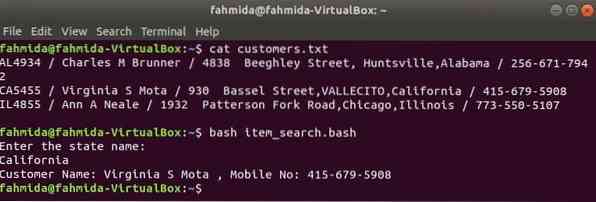
Looge bash-fail nimega item_search.bash järgmise skriptiga. Selle skripti kohaselt võetakse olekuväärtus kasutajalt ja otsitakse sisse klientidele.txt faili grep käsk ja edastati sisendina käsule awk. Awk käsk loeb 2nd ja 4th iga rea väljad. Kui sisendväärtus sobib mis tahes oleku väärtusega klientidele.txt faili, siis see prindib kliendi nimi ja mobiili number, vastasel juhul prindib see teate “Klienti ei leitud”.
item_search.bash
#!/ bin / bashecho "Sisestage riigi nimi:"
loetud olek
kliendid = 'grep "$ state" kliendid.txt | awk -F "/" 'print "Kliendi nimi:" $ 2 ",
Mobiilinumber: "$ 4"
kui ["$ kliente" != ""]; siis
kaja $ klientidele
muud
kaja "Klienti ei leitud"
fi
Väljundite kuvamiseks käivitage järgmised käsud.
$ kassi kliendid.txt$ bash item_search.bash
Väljund:
Avage sisu
awk koos sed
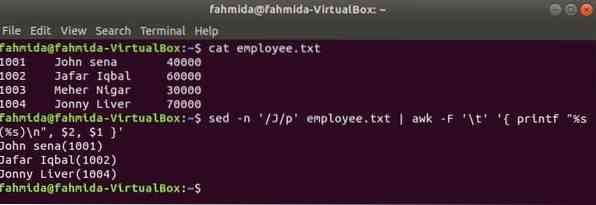
Teine kasulik Linuxi otsingu tööriist on sed. Seda käsku saab kasutada nii mis tahes faili teksti otsimiseks kui ka asendamiseks. Järgmine näide näitab käsu awk kasutamist sed käsk. Siin otsib sed-käsk kõiki töötajate nimesid, mis algavad tähega 'J'ja läheb sisendina käsule awk. awk trükib töötaja nimi ja ID pärast vormindamist.
$ kassi töötaja.txt$ sed -n '/ J / p' töötaja.txt | awk -F '\ t' 'printf "% s (% s) \ n", $ 2, $ 1'
Väljund:
Avage sisu
Järeldus:
Pärast andmete nõuetekohast filtreerimist saate käsu awk abil luua eri tüüpi aruandeid mis tahes tabeli või eraldatud andmete põhjal. Loodetavasti saate pärast selles õpetuses näidete harjutamist õppida, kuidas awk käsk töötab.


