Andmeteadus
Logistiline regressioon Pythonis
Logistiline regressioon on masinõppe klassifitseerimise algoritm. Logistiline regressioon sarnaneb ka lineaarse regressiooniga. Kuid peamine erinevus ...
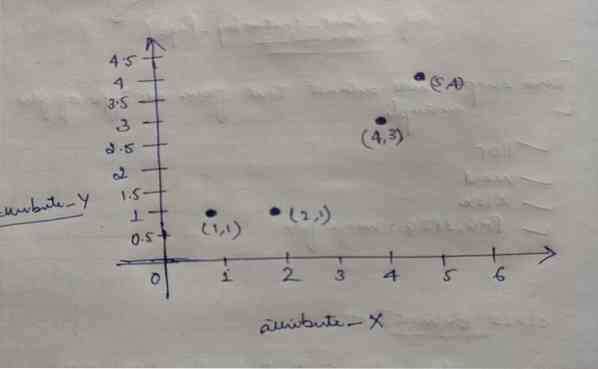
K-tähendab klastreid
Selle ajaveebi kood koos andmekogumiga on saadaval järgmisel lingil https: // github.com / shekharpandey89 / k-tähendab K-Means klastramine on järelev...

Pandas Pythonis pöördtabeli loomine
Panda püütonis sisaldab Pivot-tabel andmetabelist tuletatud summe, loendeid või liitmisfunktsioone. Liitmisfunktsioone saab kasutada erinevate funktsi...
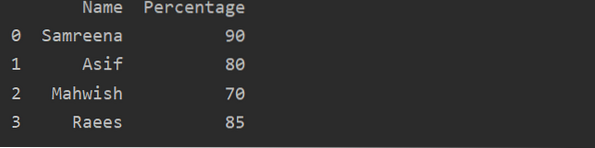
Kuidas luua Pythonis Pandas DataFrame?
Pandas DataFrame on 2D (kahemõõtmeline) märkustega andmestruktuur, milles andmed joondatakse tabelina erinevate ridade ja veergudega. Parema mõistmise...
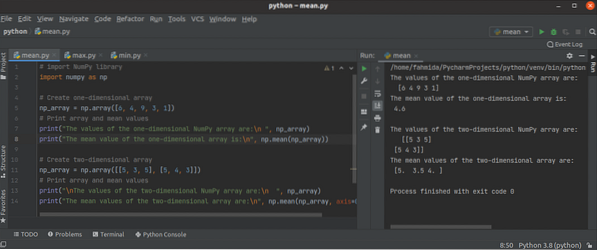
Kuidas kasutada funktsioone Python NumPy mean (), min () ja max ()?
Pythoni NumPy teegil on palju koond- või statistilisi funktsioone erinevat tüüpi ülesannete tegemiseks ühemõõtmelise või mitmemõõtmelise massiiviga. M...
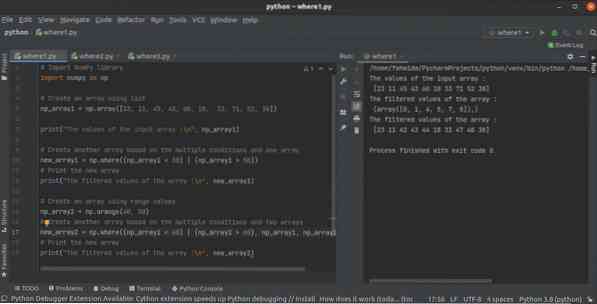
Kuidas kasutada Python NumPy kus () funktsiooni mitme tingimusega
NumPy teegil on massiivi loomiseks pythonis palju funktsioone. kus funktsioon () on üks neist massiivi loomiseks teisest NumPy massiivist ühe või mitm...
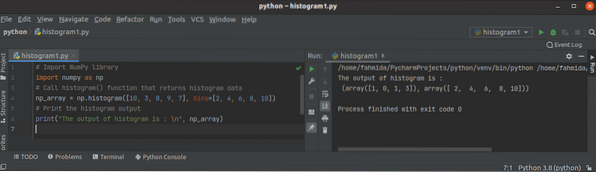
Pythoni NumPy histogrammi () õpetus
Histogramm on intervallide kaardistamine sagedustega. Seda kasutatakse konkreetse muutuja tõenäosustiheduse funktsiooni ligikaudseks hindamiseks. Seda...
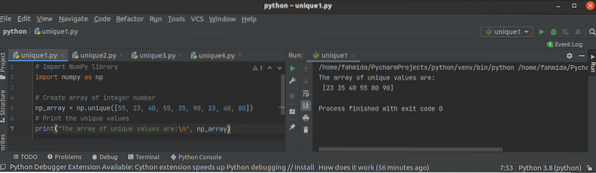
Kuidas kasutada Pythoni NumPy unikaalset () funktsiooni
NumPy teeki kasutatakse pythonis ühe või mitme mõõtmelise massiivi loomiseks ja sellel on massiiviga töötamiseks palju funktsioone. Funktsioon unikaal...
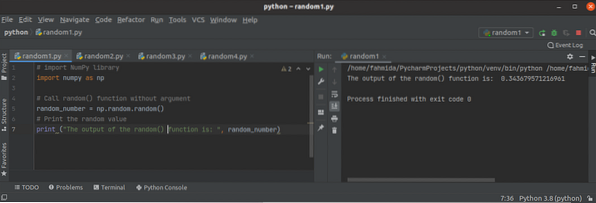
Kuidas kasutada Pythoni NumPy juhuslikku funktsiooni?
Kui numbri väärtus skripti igas teostuses muutub, nimetatakse seda arvu juhuslikuks numbriks. Juhuslikke numbreid kasutatakse peamiselt erinevat tüüpi...

