Suurandmed on andmed terabaitide või petabaitide ja suuremas järjekorras, mis koosnevad kaevandamisest, analüüsist ja suurte andmekogumite ennustavast modelleerimisest. Informatsiooni ja tehnoloogia kiire kasv on andnud ainulaadse võimaluse üksikisikutele ja ettevõtetele kogu maailmas teenida kasumit ja arendada uusi võimalusi traditsiooniliste ärimudelite ümbersõnastamiseks, kasutades ulatuslikku analüüsi.
See artikkel pakub linnulennult viit kõige populaarsemat avatud lähtekoodiga andmeplatvormi. Siin on meie loend:
Apache Hadoop
Apache Hadoop on avatud lähtekoodiga tarkvaraplatvorm, mis töötleb hajutatud keskkonnas väga suuri andmekogumeid salvestuse ja arvutusvõimsuse osas ning on peamiselt ehitatud madala hinnaga riistvarale.
Apache Hadoop on loodud selleks, et hõlpsasti laiendada paari kuni tuhande serveri arvu. See aitab teil kohapeal salvestatud andmeid töödelda üldises paralleelse töötluse seadistuses. Hadoopi üks eelis on see, et ta tegeleb tõrgetega tarkvara tasemel. Järgmine joonis illustreerib Hadoopi ökosüsteemi üldist arhitektuuri ja selle erinevaid raamistikke:
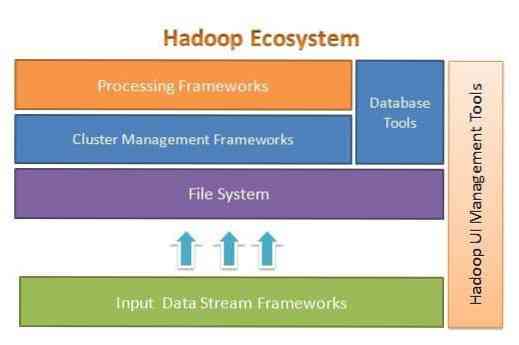
Apache Hadoop pakub raamistikku failisüsteemi kihile, klastrite haldamise kihile ja töötlemiskihile. See jätab võimaluse teistel projektidel ja raamistikel tulla ja töötada koos Hadoopi ökosüsteemiga ja töötada välja oma raamistik süsteemis saadaolevate kihtide jaoks.
Apache Hadoop koosneb neljast põhimoodulist. Need moodulid on Hadoopi hajutatud failisüsteem (failisüsteemi kiht), Hadoop MapReduce (mis töötab nii klastrihalduse kui ka töötlemiskihiga), veel üks ressursside läbirääkija (YARN, klastrihalduskiht) ja Hadoop Common.
Elasticsearch
Elasticsearch on täistekstipõhine otsingu- ja analüüsimootor. See on väga skaleeritav ja hajutatud süsteem, mis on spetsiaalselt loodud töötama tõhusalt ja kiiresti suurandmete süsteemidega, kus selle üheks peamiseks kasutusalaks on logianalüüs. See on võimeline tegema täpsemaid ja keerukamaid otsinguid ning täiustatud analüüsi ja operatiivluure jaoks peaaegu reaalajas töötlemist.
Elasticsearch on kirjutatud Java keeles ja põhineb Apache Lucene'il. Välja antud 2010. aastal ja see saavutas kiiresti populaarsuse tänu paindlikule andmestruktuurile, skaleeritavale arhitektuurile ja väga kiirele reageerimisajale. Elasticsearch põhineb skeemivaba struktuuriga JSON-dokumendil, mis muudab vastuvõtmise lihtsaks ja probleemideta. See on üks ettevõtte taseme tipptasemel otsingumootoreid. Selle kliendi saate kirjutada mis tahes programmeerimiskeeles; Elasticsearch töötab ametlikult Java-ga, .NET, PHP, Python, Perl ja nii edasi.
Elasticsearch suhtleb peamiselt REST API abil. See saab andmed kõigi nõutavate parameetritega JSON-dokumentide kujul ja annab oma vastuse sarnasel viisil.
MongoDB
MongoDB on NoSQL-i andmebaas, mis põhineb dokumendipoe andmemudelil. MongoDB-s on kõik kas kogu või dokument. MongoDB terminoloogia mõistmiseks on kogumine tabeli asendussõna, samas kui dokument on ridade asendussõna.
MongoDB on avatud lähtekoodiga, dokumendile orienteeritud ja platvormidevaheline andmebaas. See on peamiselt kirjutatud C-s++. See on ka juhtiv NoSQL-i andmebaas, mis pakub kõrget jõudlust, kõrget kättesaadavust ja hõlpsat mastaapsust. MongoDB kasutab skeemiga JSON-laadseid dokumente ja pakub rikkalikku päringutuge. Mõned selle peamistest funktsioonidest hõlmavad indekseerimist, paljundamist, koormuse tasakaalustamist, liitmist ja failide salvestamist.
Cassandra
Cassandra on avatud lähtekoodiga Apache projekt, mis on loodud NoSQL-i andmebaaside haldamiseks. Cassandra read on korraldatud tabeliteks ja indekseeritakse võtmega. See kasutab ainult liidetavat logipõhist salvestusmootorit. Cassandras olevad andmed on jaotatud mitme peata sõlme vahel, ilma ühegi rikkepunktita. See on tipptasemel Apache-projekt ja selle arendamist jälgib praegu Apache Software Foundation (ASF).
Cassandra on loodud probleemide lahendamiseks, mis on seotud suures ulatuses (veebi) kasutamisega. Arvestades Cassandra meisterlikku arhitektuuri, suudab ta jätkata toiminguid vaatamata väikesele (kuigi märkimisväärsele) arvule riistvaratõrgetele. Cassandra jookseb mitme sõlme vahel mitmes andmekeskuses. See kordab andmeid nendes andmekeskustes, et vältida tõrkeid või seisakuid. See muudab selle väga rikketaluvaks süsteemiks.
Cassandra kasutab oma sõlmede andmetele juurdepääsu saamiseks oma programmeerimiskeelt. Seda nimetatakse Cassandra päringukeeleks või CQL-ks. See sarnaneb SQL-iga, mida kasutavad peamiselt Relatsioonandmebaasid. CQL-i saab kasutada käivitades oma rakenduse nimega cqlsh. Cassandra pakub ka mitmeid integreerimisliideseid mitmele programmeerimiskeelele, et Cassandra abil rakendust luua. Selle integreerimise API toetab Java, C ++, Python ja teisi.
Apache HBase
HBase on veel üks Apache-projekt, mis on loodud NoSQL-i andmehoidla haldamiseks. Selle eesmärk on kasutada Hadoopi ökosüsteemi funktsioone, sealhulgas töökindlust, rikketaluvust ja nii edasi. See kasutab HDFS-i failisüsteemina ladustamise eesmärgil. On mitmeid andmemudeleid, millega NoSQL töötab, ja Apache HBase kuulub veergudele orienteeritud andmemudelisse. HBase põhines algselt Google Big Tableil, mis on seotud ka struktureerimata andmete veergudele orienteeritud mudeliga.
HBase salvestab kõik võtme-väärtuse paari kujul. Oluline on märkida, et HBase'is on võti ja väärtus baitide kujul. Nii et kogu teabe HBase'i salvestamiseks peate teabe teisendama baitideks. (Teisisõnu, selle API ei aktsepteeri muud kui baitide massiivi.) Olge HBase'iga ettevaatlik, kuna andmete salvestamisel peaksite meeles pidama selle algset tüüpi. Andmed, mis algselt olid stringid, tagastatakse baitide massiivina, kui neid valesti meelde tuletada. Selle tulemusena loob see teie rakenduses vea ja jookseb teie rakenduse kokku.
Loodetavasti teile see artikkel meeldis. Kui soovite arendada ja kujundada andmemahukaid rakendusi, saate tutvuda Anuj Kumari omadega Andmemahukate rakenduste arhitektuur. See raamat on teie värav nutikate andmemahukate süsteemide loomiseks, integreerides põhiandmemahukad arhitektuuriprintsiibid, mustrid ja tehnikad otse oma rakenduse arhitektuuri.


