Ülemaailmne veeb on kõigi olemasolevate andmete kõikehõlmav ja ülim allikas. Interneti kiire areng viimase kolme aastakümne jooksul on olnud enneolematu. Selle tulemusel paigaldatakse veebi iga päev sadade terabaitide arvuga andmetega.
Kõigil neil andmetel on teatud kellegi jaoks mingi väärtus. Näiteks on teie sirvimisajalugu sotsiaalmeedia rakenduste jaoks oluline, kuna nad kasutavad seda teile kuvatavate reklaamide isikupärastamiseks. Ja ka nende andmete pärast on tihe konkurents; Mõni MB rohkem andmeid võib anda ettevõtetele olulise eelise konkurentsi ees.
Andmete kaevandamine Pythoniga
Nende abistamiseks teistest, kes on andmete kraapimise uued kasutajad, oleme koostanud selle juhendi, milles näitame, kuidas andmeid veebist Python ja Beautiful supi raamatukogu abil kraapida.
Eeldame, et teil on Pythoni ja HTML-i olemasolu juba keskmiselt tuttav, kuna töötate mõlemaga järgides selles juhendis olevaid juhiseid.
Olge ettevaatlik, millistel saitidel proovite oma vastleitud andmekaevandamise oskusi, kuna paljud saidid peavad seda pealetükkivaks ja teavad, et see võib mõjutada.
Raamatukogude installimine ja ettevalmistamine
Nüüd kasutame kahte teeki, mida hakkame kasutama: pythoni päringute kogu veebilehtedelt sisu laadimiseks ja raamatu Kaunis supp protsessi tegelikuks kraapimiseks. BeautifulSoupil on alternatiive, pidage meeles ja kui olete tuttav mõne järgnevaga, kasutage neid julgelt: Scrappy, Mechanize, Selenium, Portia, kimono ja ParseHub.
Päringu kogu saab alla laadida ja installida käsuga pip järgmiselt:
# pip3 installitaotlust
Taotluste kogu peaks olema teie seadmesse installitud. Samamoodi laadige alla ka BeautifulSoup:
# pip3 installige beautifulsoup4
Sellega on meie raamatukogud valmis toiminguteks.
Nagu eelpool mainitud, pole päringute teegil muud kasutamist kui veebilehtede sisu toomine. BeautifulSoupi teegil ja päringute raamatukogudel on koht igas skriptis, mille kirjutate, ja need tuleb enne iga järgmist importida:
$ imporditaotlused$ bs4-st importib BeautifulSoupi b-dena
See lisab taotletud märksõna nimeruumi, andes Pythonile märku märksõna tähendusest alati, kui seda küsitakse. Sama juhtub märksõnaga bs, ehkki siin on meil eeliseks määrata BeautifulSoupile lihtsam märksõna.
veebileht = taotlused.hankima (URL)Ülaltoodud kood tõmbab veebilehe URL-i ja loob sellest otsese stringi, salvestades selle muutujaks.
$ webcontent = veebileht.sisuÜlaltoodud käsk kopeerib veebilehe sisu ja määrab need muutuvale veebisisule.
Sellega oleme päringute kogu ära teinud. Kõik, mis jääb teha, on muuta taotluste kogu suvandid valikuteks BeautifulSoup.
$ htmlcontent = bs (veebi sisu, “html.parser “)
See sõelub päringuobjekti ja muudab selle loetavateks HTML-objektideks.
Kui see kõik on hoolitsetud, võime liikuda tegeliku kraapimisbiti juurde.
Veebikraapimine Pythoni ja BeautifulSoupiga
Liigume edasi ja vaatame, kuidas saame BeautifulSoupi abil HTML-i andmete objektide jaoks kraapida.
Näite illustreerimiseks töötame selle selgitamise ajal selle HTML-koodilõiguga:
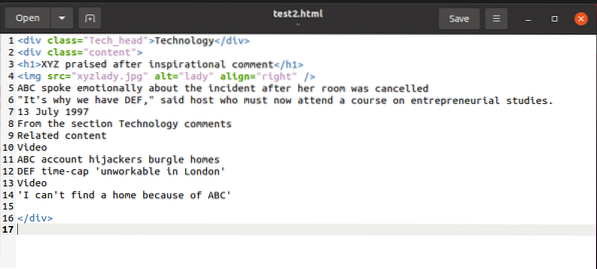
Selle koodilõigu sisule pääseb juurde teenusega BeautifulSoup ja saab seda kasutada HTML-sisumuutuja juures, nagu allpool:
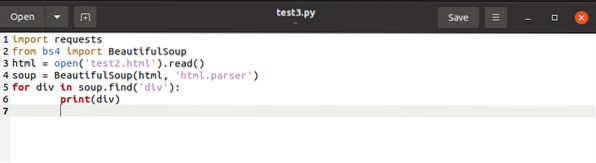
Ülaltoodud kood otsib kõiki nimetatud silte
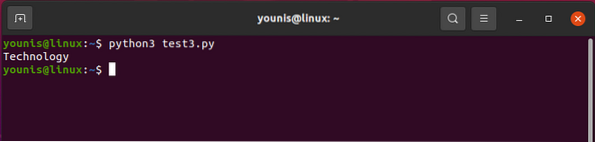
Nimega siltide samaaegseks salvestamiseks
loendisse välja andsime lõpliku koodi järgmiselt: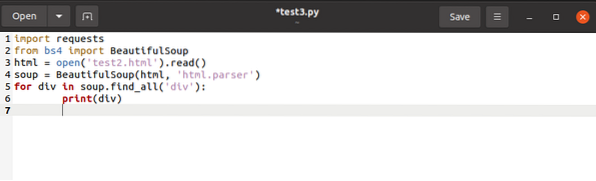
Väljund peaks naasma järgmiselt:
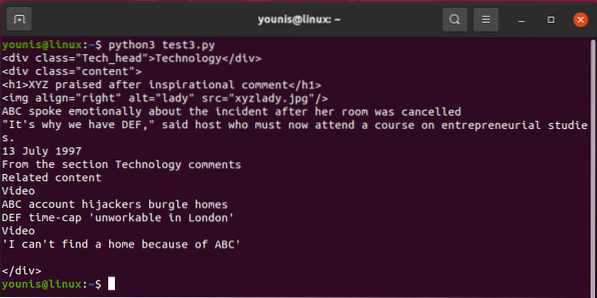
Et välja kutsuda üks
Vaatame nüüd, kuidas välja valida
silte, pidades silmas nende omadusi. Et eraldada a , meil oleks vaja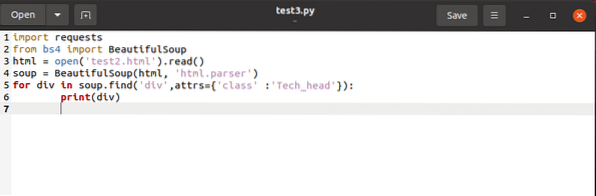
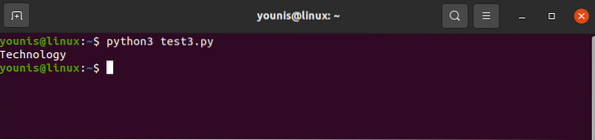
div jaoks supis.find_all ('div', attrs = 'class' = 'Tech_head'):
See tõmbab
silt.Sa saaksid:
Tehnoloogia
Kõik ilma siltideta.
Lõpuks käsitleme seda, kuidas märgendist atribuudi väärtus välja valida. Koodil peaks olema järgmine silt:
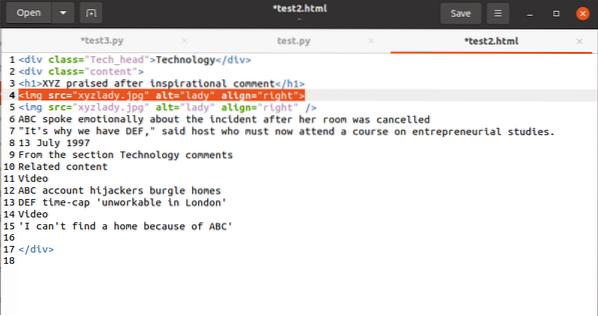

Atribuudiga src seotud väärtuse töötlemiseks kasutage järgmist:
HTML sisu.leidma („img“) [„src“]Ja väljund kujuneks välja järgmiselt:
"images_4 / a-algajatele mõeldud juhend veebi kraapimiseks-pythoni-ja-ilusa supiga.JPG "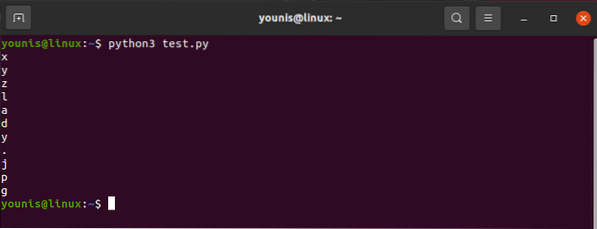
Oh poiss, see on kindlasti palju tööd!
Kui tunnete, et teie teadmine pythoni või HTML-i kohta on ebapiisav või kui olete veebi kraapimisega lihtsalt üle käinud, ärge muretsege.
Kui olete ettevõte, kes peab teatud tüüpi andmeid regulaarselt hankima, kuid ei saa ise veebi kraapida, saate selle probleemi lahendada. Kuid teadke, et see maksab teile natuke raha. Leiate kellegi, kes teie jaoks kraapimist teeb, või saate lisateabe teenuse sellistelt veebisaitidelt nagu Google ja Twitter, et andmeid teiega jagada. Need jagavad oma andmete osi API-de abil, kuid neid API-kõnesid on päevas piiratud. Peale selle võivad sellised veebisaidid nende andmeid väga kaitsta. Tavaliselt ei jaga paljud sellised saidid oma andmeid üldse.
Lõpumõtted
Enne kui kokku võtame, las ma ütlen teile valjusti, kui see pole juba olnud iseenesestmõistetav; käsud find (), find_all () on teie parimad sõbrad, kui olete BeautifulSoupiga kraapinud. Ehkki Pythoni kraapimise põhiandmete jaoks on vaja veel palju katta, peaks see juhend olema piisav neile, kes alles alustavad.


