Pange tähele, et see pole sissejuhatav õppetund. Enne selle õppetunni jätkamist lugege, mis on Apache Kafka ja kuidas see töötab, et saada sügavamat ülevaadet.
Teemad Kafkas
Kafka teema on midagi, kuhu sõnum saadetakse. Sellest teemast huvitatud tarbijarakendused tõmbavad sõnumi selle teema sisse ja saavad nende andmetega kõike teha. Kuni kindla ajani võib seda teadet suvaline arv tarbijarakendusi tõmmata mitu korda.
Mõelge sellisele teemale nagu LinuxHinti Ubuntu ajaveebi leht. Tunnid on pandud igavikku ja ükskõik kui palju huvilisi lugejaid võib tulla neid tunde lugema mitu korda või liikuda järgmisele õppetunnile vastavalt soovile. Neid lugejaid võivad huvitada ka teised LinuxHinti teemad.
Teema jaotamine
Kafka on loodud raskete rakenduste haldamiseks ja suure hulga sõnumite järjekorda jätmiseks, mis on teema sees. Kõrge tõrketaluvuse tagamiseks on iga teema jagatud mitmeks teemajaotiseks ja iga teemajaotist hallatakse eraldi sõlmes. Kui üks sõlmedest langeb, võib teine sõlm toimida teemajuhina ja serveerida teemasid huvitatud tarbijatele. Nii kirjutatakse samad andmed mitmesse teema jaotisse: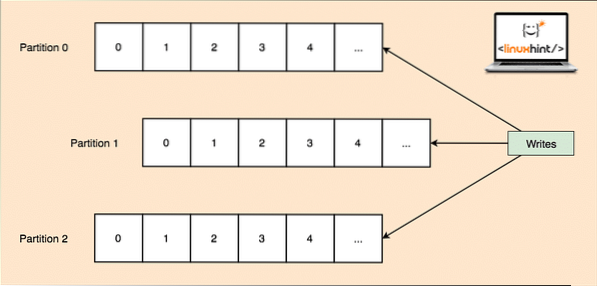
Teema vaheseinad
Nüüd näitab ülaltoodud pilt, kuidas samu andmeid paljundatakse mitmes sektsioonis. Kujutame ette, kuidas erinevad sektsioonid võivad eri sõlmedes / sektsioonides liidrina toimida:
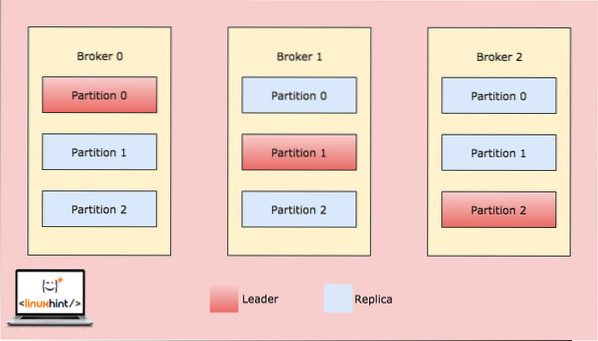
Kafka maakleri jaotamine
Kui klient kirjutab midagi teemale positsioonil, mille juht on maakler 0 partitsioon, kopeeritakse need andmed seejärel maaklerites / sõlmedes, nii et sõnum jääb ohutuks: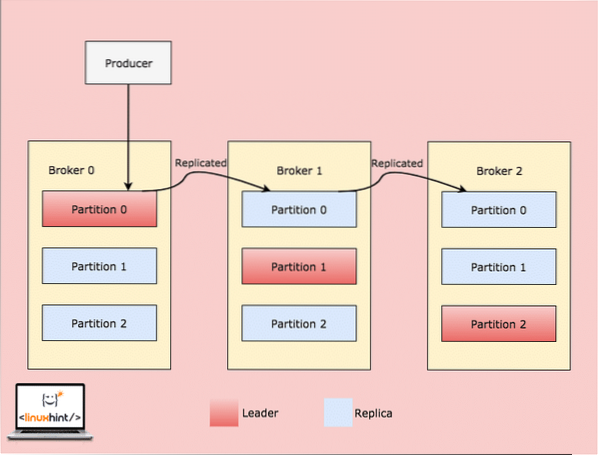
Replikatsioon maakleri partitsioonides
Rohkem vaheseinu, suurem läbilaskevõime
Kafka kasutab ära Paralleelsus pakkuda tootja ja tarbija rakendustele väga suurt tootlikkust. Tegelikult säilitab see samamoodi ka kõrge rikketaluvusega süsteemi staatuse. Mõistame, kui suur paralleelsus saavutatakse.
Kui Produceri rakendus kirjutab vahendaja 0 partitsioonile mõne sõnumi, avab Kafka paralleelselt mitu lõime, nii et sõnumit saab korrata kõigis valitud maaklerites korraga. Tarbija poolel tarbib tarbimisrakendus sõnumeid ühest sektsioonist lõime kaudu. Mida rohkem partitsioone on, seda rohkem saab avada tarbijaniidid, nii et kõik need saaksid töötada ka paralleelselt. See tähendab, et mida rohkem on klastris partitsioone, seda rohkem saab paralleelsust ära kasutada, luues väga suure läbilaskevõimega süsteemi.
Rohkem partitsioone vajab rohkem failikäsitlejaid
Nii et uurisite eespool, kuidas saaksime Kafka süsteemi jõudlust suurendada, suurendades lihtsalt partitsioonide arvu. Kuid me peame olema ettevaatlikud, millise piiri poole liigume.
Iga Kafka teema jaotis on kaardistatud serveri maakleri failisüsteemi kataloogiga, kus see töötab. Selles logikataloogis on kaks faili: üks indeksi ja teine tegelike andmete jaoks palgisegmendi kohta. Praegu avab iga maakler Kafkas iga logisegmendi indeksi- ja andmefaili jaoks failihalduri. See tähendab, et kui teil on ühel maakleril 10 000 partitsiooni, põhjustab see paralleelselt 20 000 failikäsitlejat. Kuigi see puudutab ainult maakleri konfiguratsiooni. Kui maakleri kasutusel oleval süsteemil on kõrge konfiguratsioon, pole see vaevalt probleem.
Suure partitsioonide arvuga risk
Nagu ülaltoodud piltidel nägime, kasutab Kafka klastrisisest replikatsioonitehnikat, et kopeerida juhi sõnumit teistes maaklerites asuvatele Replica partitsioonidele. Nii tootja- kui ka tarbijarakendused loevad ja kirjutavad sektsiooni, mis on praegu selle sektsiooni juht. Kui maakler ebaõnnestub, muutub selle maakleri juht kättesaamatuks. Metaandmeid selle kohta, kes on juht, hoitakse Zookeeperis. Selle metaandmete põhjal määrab Kafka partitsiooni juhtimise automaatselt teisele partitsioonile.
Kui maakler on puhta käsuga välja lülitatud, liigub Kafka klastri kontrollerisõlm seiskuva maakleri juhid järjestikku i.e. ühekaupa. kui arvestame, et ühe juhi kolimine võtab aega 5 millisekundit, siis juhtide kättesaamatus ei häiri tarbijaid, kuna see pole saadaval väga lühikese aja jooksul. Aga kui me arvestame, millal maakler tapetakse ebapuhas viisil ja see maakler sisaldab 5000 partitsiooni ja neist 2000 olid partitsioonide juhid, võtab kõigi nende partitsioonide jaoks uute juhtide määramine 10 sekundit, mis on väga kõrge nõutavad rakendused.
Järeldus
Kui arvestada kõrgetasemelise mõtlejana, toob Kafka klastri suurem partitsioon süsteemi suurema läbilaskevõime. Seda tõhusust silmas pidades tuleb kaaluda ka Kafka klastri konfiguratsiooni, mida peame säilitama, mälu, mille peame sellele klastrile määrama, ja kuidas saaksime hallata käideldavust ja latentsust, kui midagi valesti läheb.
Loe siit veel Ubuntu-põhiseid postitusi ja palju muud ka Apache kafka kohta.


