Apache Kafka
Kõrgetasemelise definitsiooni jaoks esitame Apache Kafka lühikese definitsiooni:
Apache Kafka on hajutatud, rikketaluv, horisontaalselt skaleeritav, pühendatud logi.
Need olid mõned kõrgetasemelised sõnad Apache Kafka kohta. Mõistkem siin mõistetest üksikasjalikult.
- Levitatakse: Kafka jagab selles olevad andmed mitmesse serverisse ja igaüks neist serveritest suudab klientide päringuid käsitleda selles sisalduvate andmete osas
- Rikkekindel: Kafkal pole ühtegi ebaõnnestumispunkti. SPoF-süsteemis, nagu MySQL-i andmebaasis, kui andmebaasi majutav server langeb, keeratakse rakendus kruvidega. Süsteemis, millel pole SPoF-i ja mis koosneb mitmest sõlmest, isegi kui suurem osa süsteemist langeb, on see lõppkasutaja jaoks ikka sama.
- Horisontaalselt skaleeritav: Selline röövimine viitab olemasolevate klastrite lisamisele masinatele. See tähendab, et Apache Kafka on võimeline aktsepteerima oma klastris rohkem sõlme ja pakkuma süsteemi nõutavate täienduste jaoks seisakuid. Kelmuse mõistete tüübi mõistmiseks vaadake allolevat pilti:
- Kohusta logi: Kohustuslik logi on andmestruktuur nagu lingitud loend. See lisab mis tahes sõnumid, milleni see jõuab, ja hoiab alati nende järjekorda. Andmeid ei saa sellest logist kustutada enne, kui nende andmete jaoks on saavutatud määratud aeg.
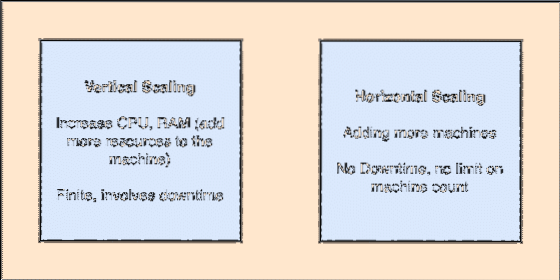
Vertikaalne ja horisontaalne scailing
Apache Kafka teema on täpselt nagu järjekord, kuhu sõnumeid salvestatakse. Neid teateid salvestatakse konfigureeritava aja vältel ja sõnumeid ei kustutata enne selle aja saavutamist, isegi kui seda on tarbinud kõik teadaolevad tarbijad.
Kafka on skaleeritav, kuna just tarbijad salvestavad tegelikult selle, et mis sõnumi nad said, on see nihkeväärtusena. Vaatame joonist, et sellest paremini aru saada: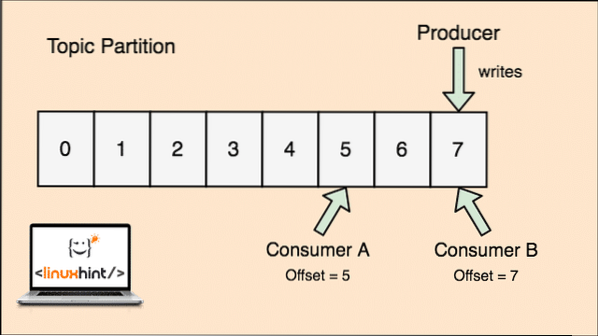
Teema partitsioon ja tarbija tasaarvestus Apache Kafkas
Apache Kafkaga alustamine
Apache Kafka kasutamise alustamiseks peab see olema arvutisse installitud. Selleks lugege artiklit Apache Kafka installimine Ubuntu.
Veenduge, et teil oleks aktiivne Kafka install, kui soovite proovida näiteid, mida me tunnis hiljem esitame.
Kuidas see töötab?
Kafkaga koos Produtsent rakendused avaldavad sõnumeid mis saabub Kafkasse Sõlm ja mitte otse Tarbijale. Selle Kafka sõlme kaudu tarbib sõnumeid Tarbija rakendused.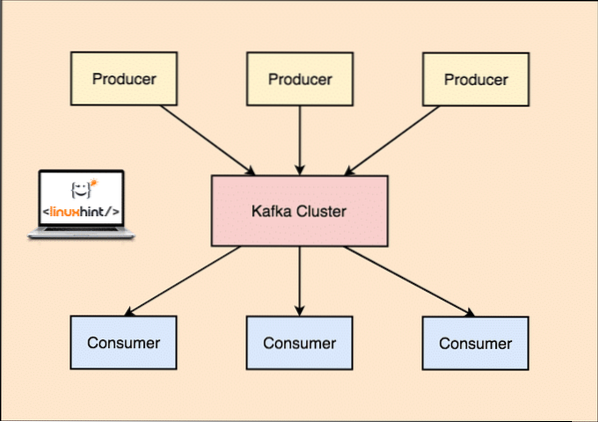
Kafka tootja ja tarbija
Kuna üks teema võib korraga saada palju andmeid, on Kafka horisontaalselt skaleeritavuse hoidmiseks jagatud vaheseinad ja iga sektsioon võib elada klastri mis tahes sõlmpunktis. Proovime seda esitada:
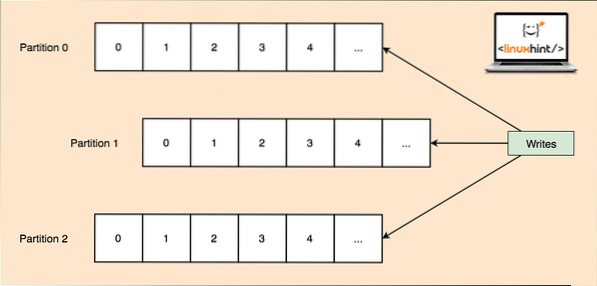
Teema vaheseinad
Kafka maakler jällegi ei pea arvestust selle üle, milline tarbija on tarbinud mitu andmepaketti. See on tarbijate kohustus jälgida tarbitud andmeid.
Püsivus kettale
Kafka säilitab Producersilt saadud kettadokumente ja ei hoia neid mälus. Võib tekkida küsimus, kuidas see muudab asja teostatavaks ja kiireks? Selle taga oli mitu põhjust, mis muudab selle sõnumikirjete haldamiseks optimaalseks viisiks:
- Kafka järgib sõnumikirjete grupeerimise protokolli. Tootjad toodavad teateid, mis püsivad kettadena suurte tükkidena ja tarbijad tarbivad neid sõnumikirjeid ka suurte lineaarsete tükkidena.
- Ketta kirjutamise põhjus on lineaarne, kuna see muudab lugemise kiireks tänu kettal väga lühikesele lugemisajale.
- Lineaarse ketta toiminguid optimeerib Operatsioonisüsteemid samuti kasutades kirjutamine taga ja ettelugemine.
- Ka kaasaegne operatsioonisüsteem kasutab mõistet Pagecaching mis tähendab, et nad salvestavad vahemälus osa kettaandmeid vabas vabas RAM-is.
- Kuna Kafka säilitab andmeid ühtsetes standardandmetes kogu voos alates tootjast tarbijani, kasutab ta seda nullkoopia optimeerimine protsess.
Andmete levitamine ja replikatsioon
Nagu me eespool uurisime, et teema on jagatud partitsioonideks, kopeeritakse iga sõnumikirje klastri mitmesse sõlme, et säilitada iga kirje järjekord ja andmed juhul, kui üks sõlm sureb.
Kuigi sektsiooni paljundatakse mitmel sõlmel, on siiski olemas partitsioonijuht sõlm, mille kaudu rakendused loevad ja kirjutavad andmeid selle teema kohta ning juht kordab teiste sõlmede andmeid, mida nimetatakse järgijad selle sektsiooni.
Kui sõnumikirje andmed on rakenduse jaoks väga olulised, saab sõnumikirje turvalisust ühes sõlmpunktis suurendada, suurendades replikatsioonitegur klastri.
Mis on Zookeeper?
Zookeeper on väga rikketaluv, hajutatud võtmeväärtusega kauplus. Apache Kafka sõltub suuresti Zookeeperist klastrite mehaanika salvestamiseks, nagu südamelöök, värskenduste / konfiguratsioonide levitamine jne).
See võimaldab Kafka maakleritel end tellida ja teada, kui partitsioonijuhi ja sõlmpunktide jaotuse osas on toimunud muudatusi.
Tootja- ja tarbijarakendused suhtlevad otse Zookeeperiga rakendus, et teada saada, milline sõlm on teema partitsioonijuht, et nad saaksid partitsioonijuhilt lugeda ja kirjutada.
Voogesitus
Voogprotsessor on Kafka klastri põhikomponent, mis võtab sisendteemadelt pideva sõnumikirjete andmete voo, töötleb neid andmeid ja loob andmevoo väljundteemadeks, mis võivad olla ükskõik millised, prügikastist andmebaasini.
Lihtsat töötlemist on täiesti võimalik teha otse tootja / tarbija API-de abil, kuigi keerukaks töötlemiseks, näiteks voogude ühendamiseks, pakub Kafka integreeritud voogude API teeki, kuid pange tähele, et see API on mõeldud kasutamiseks meie enda koodibaasis ja seda ei tehta " ei jookse maakleri peal. See töötab sarnaselt tarbija API-ga ja aitab meil voogude töötlemist mitme rakenduse jaoks laiendada.
Millal Apache Kafkat kasutada?
Nagu uurisime ülaltoodud jaotistes, saab Apache Kafkat kasutada suure hulga sõnumikirjete käsitlemiseks, mis võivad kuuluda meie süsteemide praktiliselt lõpmatule hulgale teemadele.
Apache Kafka on ideaalne kandidaat teenuse kasutamisel, mis võimaldab meil rakendustes sündmustepõhist arhitektuuri jälgida. Selle põhjuseks on andmete püsivuse, tõrketaluvuse ja väga hajutatud arhitektuuri võimalused, kus kriitilised rakendused saavad tugineda selle jõudlusele.
Kafka skaleeritav ja hajutatud arhitektuur muudab integreerimise mikroteenustega väga lihtsaks ning võimaldab rakendusel eraldada end suure äriloogikaga.
Uue teema loomine
Saame luua testteema testimine Apache Kafka serveris järgmise käsuga:
Teema loomine
sudo kafka-teemad.sh --create --zookeeper localhost: 2181 - replikatsioonitegur 1--partitsioonid 1 - teema testimine
Selle käsuga saame tagasi: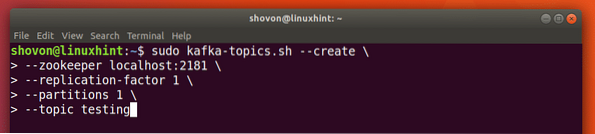
Looge uus Kafka teema
Luuakse testimise teema, mida saame kinnitada mainitud käsuga:
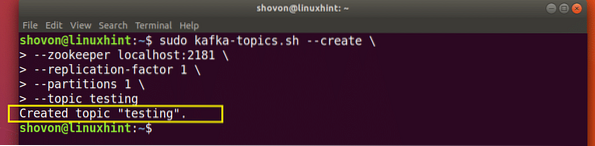
Kafka teema loomise kinnitus
Sõnumite kirjutamine teemal
Nagu me varem uurisime, on üks Apache Kafkas esinevatest API-dest Tootja API. Kasutame seda API-d uue sõnumi loomiseks ja avaldamiseks just loodud teemal:
Sõnumi kirjutamine teemale
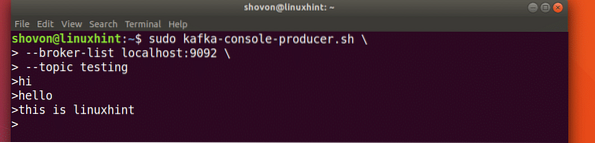
sudo kafka-konsooli tootja.sh - maaklerite nimekiri localhost: 9092 - teemaline testimineVaatame selle käsu väljundit:
Avaldage sõnum Kafka teemas
Kui vajutame klahvi, näeme uut noole (>) märki, mis tähendab, et võime nüüd andmeid sisestada:

Sõnumi sisestamine
Sisestage lihtsalt midagi ja vajutage uue rea alustamiseks. Sisestasin 3 rida tekste:
Sõnumite lugemine teemast
Nüüd, kui oleme oma loodud Kafka teemal avaldanud teate, on see sõnum veel mõnda aega seadistatav. Saame seda nüüd lugeda, kasutades Tarbija API:
Sõnumite lugemine teemast
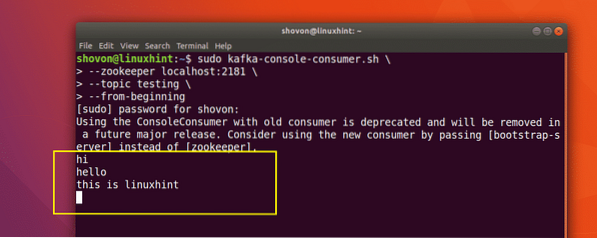
sudo kafka-konsooli-tarbija.sh - zookeeper localhost: 2181 --teema testimine - algusest peale
Selle käsuga saame tagasi:
Käsk lugeda sõnumit Kafka teemalt
Me näeme Produceri API abil kirjutatud sõnumeid või ridu, nagu allpool näidatud:
Kui kirjutame Produceri API abil veel ühe uue sõnumi, kuvatakse see kohe ka tarbija poolel:
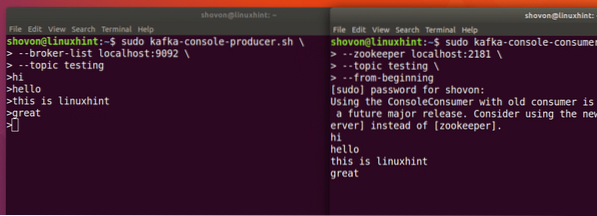
Avaldamine ja tarbimine samaaegselt
Järeldus
Selles tunnis vaatasime, kuidas hakkame kasutama Apache Kafkat, mis on suurepärane sõnumimaakler ja võib toimida ka spetsiaalse andmete püsivuse üksusena.


