1. osa: Ühe sõlme seadistamine
Täna on dokumentide või andmete elektrooniline salvestamine salvestusseadmesse nii kiire kui ka lihtne, samuti on see suhteliselt odav. Kasutuses on failinime viide, mis on mõeldud dokumendi kirjeldamiseks. Teise võimalusena hoitakse andmeid andmebaaside haldussüsteemis (DBMS) nagu PostgreSQL, MariaDB või MongoDB, et nimetada vaid mõnda võimalust. Arvutiga on kas kohapeal või kaugühendusega ühendatud mitu andmekandjat, näiteks USB-mälupulk, sisemine või väline kõvaketas, võrguga ühendatud salvestusruum (NAS), pilvemälu või GPU / Flash-põhine, nagu Nvidia V100-s [10].
Seevastu vastupidine protsess, õigete dokumentide leidmine dokumendikogust, on üsna keeruline. Enamasti nõuab see failivormingu veata tuvastamist, dokumendi indekseerimist ja võtmemõistete väljavõtmist (dokumendi klassifikatsioon). Siit tuleb Apache Solri raamistik. See pakub praktilist liidest mainitud sammude tegemiseks - dokumendiregistri koostamine, otsingupäringute aktsepteerimine, tegeliku otsingu tegemine ja otsingutulemite tagastamine. Apache Solr on seega andmebaasi või dokumendisilo tõhusaks uurimiseks tuum.
Sellest artiklist saate teada, kuidas Apache Solr töötab, kuidas seadistada ühte sõlme, indekseerida dokumente, teha otsingut ja hankida tulemus.
Järgnevad artiklid tuginevad sellele artiklile ja neis käsitleme teisi spetsiifilisemaid kasutusjuhtumeid, nagu PostgreSQL DBMS-i integreerimine andmeallikana või koormuse tasakaalustamine mitme sõlme vahel.
Apache Solri projekti kohta
Apache Solr on otsingumootori raamistik, mis põhineb võimsal Lucene otsinguindeksiserveril [2]. Java-s kirjutatuna hoitakse seda Apache Software Foundationi (ASF) katuse all [6]. See on Apache 2 litsentsi alusel vabalt saadaval.
Teemal “Leia dokumendid ja andmed uuesti” on tarkvaramaailmas väga oluline roll ja paljud arendajad tegelevad sellega intensiivselt. Veebisait Awesomeopensource [4] loetleb üle 150 otsingumootori avatud lähtekoodiga projekti. Alates 2021. aasta algusest on ElasticSearch [8] ja Apache Solr / Lucene suuremate andmekogumite otsimisel kaks parimat koera. Otsingumootori arendamine nõuab palju teadmisi, Frank teeb seda Pythoni põhise AdvaS Advanced Search [3] teegiga alates 2002. aastast.
Apache Solri seadistamine:
Apache Solri installimine ja kasutamine pole keeruline, see on lihtsalt terve rida toiminguid, mille peate ise läbi viima. Esimese andmepäringu tulemuseks võib olla umbes 1 tund. Pealegi pole Apache Solr pelgalt hobiprojekt, vaid seda kasutatakse ka professionaalses keskkonnas. Seetõttu on valitud operatsioonisüsteemi keskkond mõeldud pikaajaliseks kasutamiseks.
Selle artikli baaskeskkonnana kasutame Debiani GNU / Linux 11, mis on eelseisev Debiani väljaanne (alates 2021. aasta algusest) ja mis peaks eeldatavasti olema saadaval 2021. aasta keskel. Selle õpetuse jaoks eeldame, et olete selle juba installinud - kas natiivsüsteemina - virtuaalsesse masinasse nagu VirtualBox või AWS-i konteinerisse.
Peale põhikomponentide peate süsteemi installima järgmised tarkvarapaketid:
- Curl
- Vaikimisi java
- Libcommons-cli-java
- Libxerces2-java
- Libtika-java (Apache Tika projekti raamatukogu [11])
Need paketid on Debiani GNU / Linuxi standardkomponendid. Kui see pole veel installitud, saate need korraga installida administraatoriõigustega kasutajana, näiteks root või sudo kaudu, näidatud järgmiselt:
# apt-get install curl default-java libcommons-cli-java libxerces2-java libtika-javaPärast keskkonna ettevalmistamist on 2. samm Apache Solri installimine. Praeguse seisuga pole Apache Solr tavalise Debiani paketina saadaval. Seetõttu on vajalik Apache Solr 8 hankimine.8 projekti veebisaidi allalaadimise jaotisest [9]. Selle salvestamiseks oma süsteemi kataloogi / tmp kasutage allolevat käsku wget:
$ wget -O / tmp https: // allalaadimine.apache.org / lutseen / solr / 8.8.0 / solr-8.8.0.tgzLüliti -O lühendab -output-dokumenti ja paneb wget talletama tõrva.gz fail antud kataloogis. Arhiivi suurus on umbes 190 miljonit. Järgmisena pakkige arhiiv tõrva abil kataloogi / opt lahti. Selle tulemusena leiate kaks alamkataloogi - / opt / solr ja / opt / solr-8.8.0, kusjuures / opt / solr on seatud sümboolse lingina viimasele. Apache Solr on varustatud seadistuskriptiga, mille käivitate järgmisena, see on järgmine:
# / opt / solr-8.8.0 / bin / install_solr_service.shSelle tulemusel luuakse Linuxi kasutaja solr töötab Solri teenuses ning tema kodukataloog kataloogis / var / solr loob Solri teenuse, lisatakse koos vastavate sõlmedega ja käivitatakse Solri teenus pordil 8983. Need on vaikeväärtused. Kui te pole nendega rahul, saate neid installimise ajal muuta või isegi hiljem, kuna installiskript aktsepteerib seadistuste kohandamiseks vastavaid lüliteid. Nende parameetrite kohta soovitame tutvuda Apache Solri dokumentatsiooniga.
Solri tarkvara on korraldatud järgmistesse kataloogidesse:
- prügikast
sisaldab Solri kahendfaile ja faile Solri käitamiseks teenusena - kaastöö
välised Solri teegid, näiteks andmete importimise käitleja ja Lucene teegid - dist
sisemised Solri teegid - dokumendid
link veebis kättesaadavale Solri dokumentatsioonile - näide
andmekogumite näited või mitu kasutusjuhtu / stsenaariumi - litsentsidega
tarkvaralitsentsid Solri erinevate komponentide jaoks - server
serveri konfiguratsioonifailid, näiteks server / etc teenuste ja portide jaoks
Nende kataloogide kohta saate lugeda Apache Solri dokumentatsioonist [12].
Apache Solri haldamine:
Apache Solr töötab teenusena taustal. Saate seda käivitada kahel viisil, kasutades administraatoriõigustega kasutajana systemctl (esimene rida) või otse kataloogist Solr (teine rida). Allpool loetleme mõlemad terminali käsud:
# systemctl start solr$ solr / bin / solr algus
Apache Solri peatamine toimub sarnaselt:
# systemctl stop solr$ solr / bin / solr stop
Samamoodi käib ka Apache Solri teenuse taaskäivitamine:
# systemctl taaskäivitage solr$ solr / bin / solr taaskäivitage
Lisaks saab Apache Solri protsessi olekut kuvada järgmiselt:
# systemctl olekus solr$ solr / bin / solr olek
Väljundis on loetletud käivitatud teenusefail, nii vastav ajatempel kui ka logiteated. Alloleval joonisel on näidatud, et Apache Solri teenus käivitati pordis 8983 protsessiga 632. Protsess töötab edukalt 38 minutit.
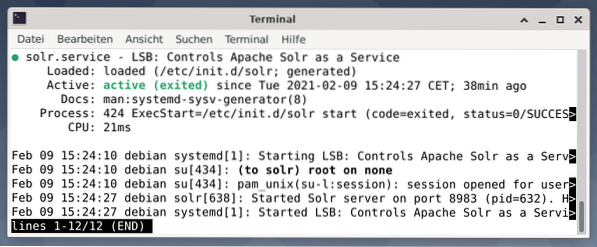
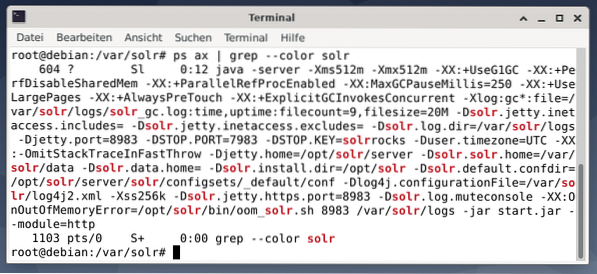
Apache Solri protsessi aktiivsuse kontrollimiseks võite ristkontrollida ka käsuga ps koos grep-iga. See piirab ps-i väljundi kõigi praegu aktiivsete Apache Solri protsessidega.
# ps kirves | grep - värv solrAllolev joonis näitab seda ühe protsessi puhul. Näete Java kõnet, millele on lisatud parameetrite loend, näiteks mälukasutuse (512M) pordid, et kuulata päringuid 8983, peatamisnõudeid 7983 ja ühenduse tüüp (http).
Kasutajate lisamine:
Apache Solri protsessid töötavad konkreetse kasutajaga nimega solr. See kasutaja on abiks Solri protsesside haldamisel, andmete üleslaadimisel ja päringute saatmisel. Seadistamisel pole kasutaja solril parooli ja eeldatavasti on tal edasiseks toimimiseks sisse logida. Määrake kasutaja solr nagu kasutaja juur parool, see kuvatakse järgmiselt:
# passwd solrSolri haldus:
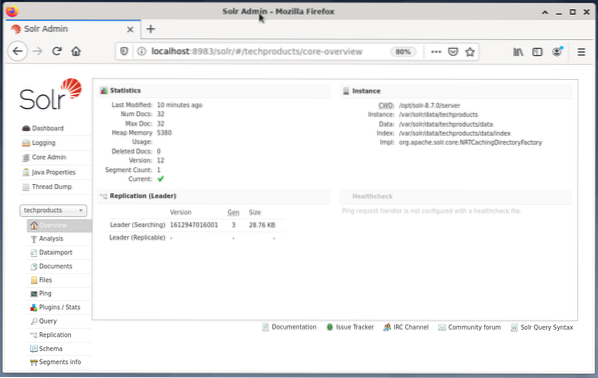
Apache Solri haldamine toimub Solri juhtpaneeli abil. Sellele pääseb juurde veebibrauseri kaudu aadressilt http: // localhost: 8983 / solr. Allpool olev joonis näitab põhivaadet.
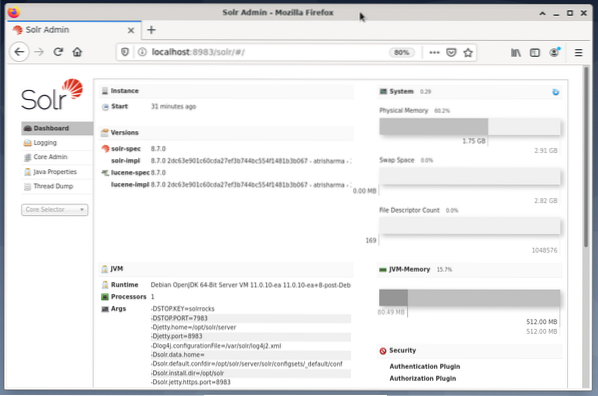
Vasakul näete peamenüüd, mis viib teid logimise, Solri tuumade haldamise, Java seadistuste ja olekuteabe alajaotusteni. Valige soovitud tuum, kasutades menüü all asuvat valikukasti. Menüü paremas servas kuvatakse vastav teave. Armatuurlaua menüükirje sisaldab üksikasju Apache Solri protsessi kohta, samuti praegust koormust ja mälukasutust.
Pange tähele, et armatuurlaua sisu muutub sõltuvalt Solri tuumade arvust ja indekseeritud dokumentidest. Muudatused mõjutavad nii menüüelemente kui ka vastavat teavet, mis on nähtav paremal.
Otsingumootorite töö mõistmine:
Lihtsamalt öeldes analüüsivad otsingumootorid dokumente, kategoriseerivad need ja võimaldavad teil otsida nende kategooriate alusel. Põhimõtteliselt koosneb protsess kolmest etapist, mida nimetatakse indekseerimiseks, indekseerimiseks ja järjestamiseks [13].
Roomamine on esimene etapp ja kirjeldab protsessi, mille käigus kogutakse uut ja uuendatud sisu. Otsingumootor kasutab roboteid, mis on tuntud ka kui ämblikud või roomikud, sellest tulenevalt on olemasolevate dokumentide läbimiseks termin roomamine.
Teist etappi nimetatakse indekseerimine. Varem kogutud sisu muudetakse otsitavaks, teisendades originaaldokumendid vormingusse, mida otsingumootor mõistab. Märksõnad ja mõisted eraldatakse ja salvestatakse (massilistesse) andmebaasidesse.
Kolmandat etappi nimetatakse paremusjärjestus ja kirjeldab otsingutulemuste sortimise protsessi vastavalt nende asjakohasusele otsingupäringuga. On tavaline, et tulemused kuvatakse kahanevas järjekorras, nii et esimene, mis on kõige olulisem otsija päringu jaoks, oleks esimene.
Apache Solr töötab sarnaselt eelnevalt kirjeldatud kolmeastmelise protsessiga. Sarnaselt populaarsele otsingumootorile Google kasutab ka Apache Solr erinevatest allikatest pärit dokumentide kogumise, salvestamise ja indekseerimise järjestust ning muudab need kättesaadavaks / otsitavaks peaaegu reaalajas.
Apache Solr kasutab dokumentide indekseerimiseks erinevaid viise, sealhulgas järgmisi [14]:
- Indeksitaotluste halduri kasutamine dokumentide otse Solrisse üleslaadimisel. Need dokumendid peaksid olema JSON-, XML / XSLT- või CSV-vormingus.
- Väljavõtete taotluste käitleja (Solr Cell) kasutamine. Dokumendid peaksid olema PDF- või Office-vormingus, mida toetab Apache Tika.
- Kasutades Data Import Handlerit, mis edastab andmeid andmebaasist ja kataloogib need veergude nimede abil. Andmete importimise haldur tõmbab allikatena andmeid meilidest, RSS-voogudest, XML-andmetest, andmebaasidest ja lihttekstifailidest.
Päringukäsitlejat kasutatakse Apache Solris otsingu päringu saatmisel. Päringukäitleja analüüsib antud päringut indeksikäsitleja sama kontseptsiooni alusel, et see vastaks päringule ja varem indekseeritud dokumentidele. Matšid järjestatakse vastavalt nende sobivusele või asjakohasusele. Lühike näide päringutest on toodud allpool.
Dokumentide üleslaadimine:
Lihtsuse huvides kasutame järgmise näite jaoks andmekogumi näidist, mille Apache Solr juba pakub. Dokumentide üleslaadimine toimub kasutaja lahendustena. 1. samm on tuuma loomine nimega techproducts (paljude tehniliste toodete jaoks).
$ solr / bin / solr loo -c tehnilisi tooteid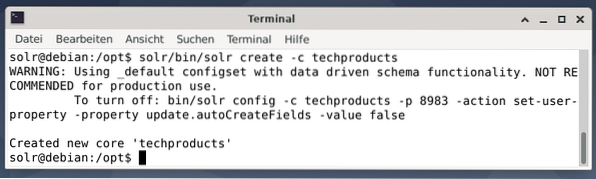
Kõik on korras, kui näete teadet „Loodud uued põhitooted”. 2. samm lisatakse andmed (XML-andmed eksemplaridest) varem loodud põhitehnoloogiatoodetele. Kasutusel on tööriista postitus, mille parameetrid on -c (tuuma nimi) ja üleslaaditavad dokumendid.
$ solr / bin / post -c techproducts solr / example / exampledocs / *.xmlSelle tulemuseks on allpool näidatud väljund ja see sisaldab kogu kõnet ning 14 indekseeritud dokumenti.
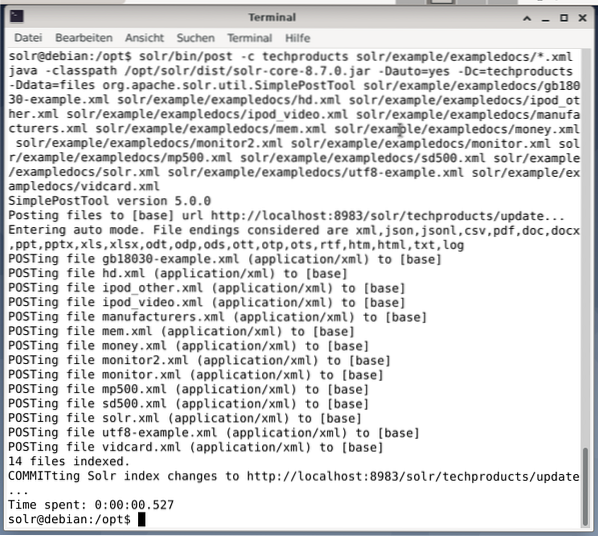
Samuti näitab juhtpaneel muudatusi. Uus kirje nimega techproducts on nähtav vasakpoolses rippmenüüs ja paremal küljel on vastavate dokumentide arv muutunud. Kahjuks pole toorandmekogumite üksikasjalik vaade võimalik.
Kui tuum / kogu tuleb eemaldada, kasutage järgmist käsku:
$ solr / bin / solr delete -c tehnilised tootedAndmete pärimine:
Apache Solr pakub andmete pärimiseks kahte liidest: veebipõhise juhtpaneeli ja käsurea kaudu. Mõlemat meetodit selgitame allpool.
Päringute saatmine Solri juhtpaneeli kaudu toimub järgmiselt:
- Valige rippmenüüst sõlmede techproducts.
- Valige rippmenüü all olevast menüüst kirje Päring.
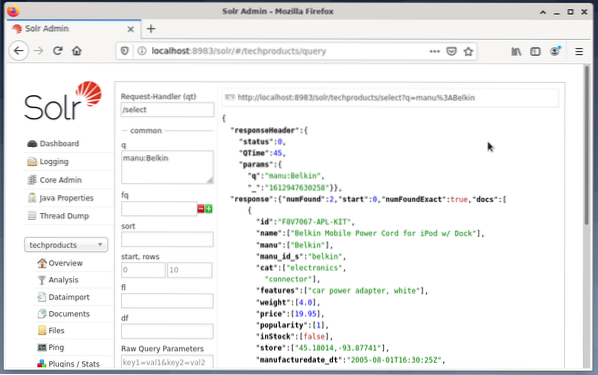
Paremal küljel ilmuvad sisestusväljad, et sõnastada päring, näiteks päringu käitleja (qt), päring (q) ja sortimisjärjestus (sort). - Valige sisestusväli Päring ja muutke sisestuse sisu väärtusest “*: *” väärtuseks “manu: Belkin”. See piirab otsingu „kõik väljad kõigi kirjetega” kuni „andmekogumitega, mille manu-väljal on nimi Belkin”. Sellisel juhul lühendab nimi näide andmekogumis tootjat.
- Järgmiseks vajutage nuppu Execute Query. Tulemuseks on peal trükitud HTTP-päring ja allpool JSON-vormingus otsingupäringu tulemus.
Käsurida aktsepteerib sama päringut nagu armatuurlaual. Erinevus seisneb selles, et peate teadma päringuväljade nime. Ülaltoodud päringu saatmiseks peate terminalis käivitama järgmise käsu:
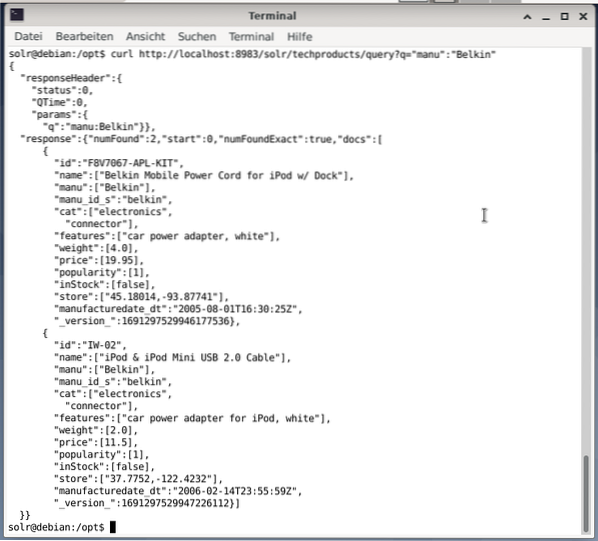
$ curlhttp: // localhost: 8983 / solr / techproducts / query?q = ”manu”: ”Belkin
Väljund on JSON-vormingus, nagu allpool näidatud. Tulemus koosneb vastuse päisest ja tegelikust vastusest. Vastus koosneb kahest andmekogumist.
Pakendamine:
Palju õnne! Esimese etapi olete edukalt saavutanud. Põhitaristu on loodud ja olete õppinud, kuidas dokumente üles laadida ja päringuid esitada.
Järgmine samm hõlmab seda, kuidas täpsustada päringut, sõnastada keerukamaid päringuid ja mõista Apache Solri päringulehe pakutavaid erinevaid veebivorme. Samuti arutame, kuidas otsingutulemit järeltöödelda, kasutades erinevaid väljundvorminguid, nagu XML, CSV ja JSON.
Autorite kohta:
Jacqui Kabeta on keskkonnakaitsja, innukas uurija, koolitaja ja mentor. Mitmes Aafrika riigis on ta töötanud IT-tööstuses ja vabaühenduste keskkonnas.
Frank Hofmann on IT-arendaja, koolitaja ja autor ning eelistab töötada Berliinist, Genfist ja Kaplinnast. Debiani paketihalduse raamatu kaasautor, mis on saadaval veebisaidilt dpmb.org
- [1] Apache Solr, https: // lutseen.apache.org / solr /
- [2] Lucene'i otsingukogu, https: // lucene.apache.org /
- [3] AdvaSi täpsem otsing, https: // pypi.org / projekt / AdvaS-Täpsem-Otsing /
- [4] Otsingumootori 165 parimat avatud lähtekoodiga projekti, https: // awesomeopensource.com / projektid / otsingumootor
- [5] ElasticSearch, https: // www.elastne.co / de / elasticsearch /
- [6] Apache Software Foundation (ASF), https: // www.apache.org /
- [7] FESS, https: // fess.koodelibid.org / register.HTML
- [8] ElasticSearch, https: // www.elastne.kaas / de /
- [9] Apache Solr, jaotis Allalaadimine, https: // lutseen.apache.org / solr / downloads.htm
- [10] Nvidia V100, https: // www.nvidia.com / et-us / andmekeskus / v100 /
- [11] Apache Tika, https: // tikai.apache.org /
- [12] Apache Solri kataloogipaigutus, https: // lucene.apache.org / solr / guide / 8_8 / install-solr.html # kataloogipaigutus
- [13] Kuidas töötavad otsingumootorid: indekseerimine, indekseerimine ja paremusjärjestus. SEO algajate juhend https: // moz.com / algajad-juhend SEO-le / kuidas-otsingumootorid töötavad
- [14] Alustage Apache Solriga, https: // sematext.com / guides / solr / #: ~: text = Solr% 20works% 20by% 20gathering% 2C% 20storing,% 20huge% 20volumes% 20of% 20data


