Rääkides hajutatud süsteemidest nagu ülal, puutume kokku analüüsi ja jälgimise probleemiga. Iga sõlm genereerib palju teavet oma tervise (protsessori kasutus, mälu jne) ja rakenduse oleku ning kasutajate proovide kohta. Need üksikasjad tuleb registreerida:
- Samas järjekorras, milles nad on loodud,
- Eraldatud kiireloomulisuse (reaalajas analüütika või andmepartiid) ja mis kõige tähtsam,
- Nende kogumise mehhanism peab ise olema hajutatud ja skaleeritav, vastasel juhul jääb meile üks ebaõnnestumispunkt. Midagi, mida hajutatud süsteemi disain pidi vältima.
Miks kasutada Kafkat?
Apache Kafka on levitatud voogesituse platvorm. Kafka keeles, Produtsendid pidevalt andmeid genereerida (ojad) ja Tarbijad vastutavad selle töötlemise, säilitamise ja analüüsimise eest. Kafka Maaklerid vastutavad selle eest, et hajutatud stsenaariumi korral jõuaksid andmed tootjatelt tarbijateni ilma vastuoludeta. Kafka maaklerite komplekt ja veel üks tarkvara loomaaiatalitaja moodustavad tüüpilise Kafka kasutuselevõtu.
Paljude tootjate andmete voog tuleb kokku liita, jaotada ja saata mitmele tarbijale. Seal on palju segamist. Järjepidevuse vältimine pole lihtne ülesanne. Seetõttu vajame Kafkat.
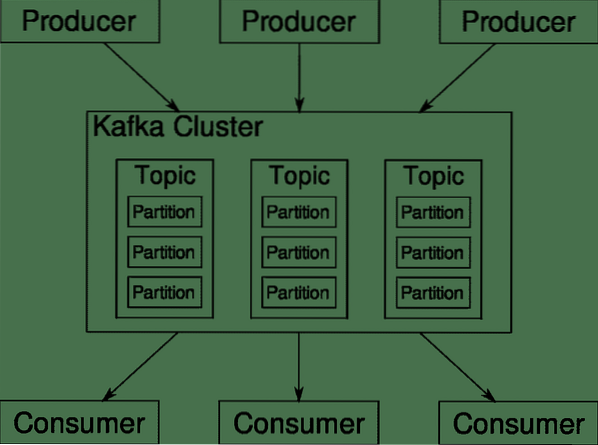
Stsenaariumid, kus Kafkat saab kasutada, on üsna mitmekesine. Kõik, alates IOT-seadmetest kuni VM-ide klastrini kuni teie enda kohapeal asuvatesse paljasmetalliserveritesse. Kõikjal, kus paljud asjad korraga tahavad teie tähelepanu .. .See pole eriti teaduslik? Kafka arhitektuur on omaette jäneseauk ja väärib iseseisvat kohtlemist. Vaatame kõigepealt tarkvara väga pinnataset.
Docker Compose'i kasutamine
Ükskõik millisel fantaasiarikkal viisil otsustate Kafkat kasutada, on üks asi kindel - te ei kasuta seda ühe eksemplarina. See pole mõeldud selliseks kasutamiseks ja isegi kui teie levitatud rakendus vajab praegu ainult ühte eksemplari (maaklerit), siis see lõpuks kasvab ja peate veenduma, et Kafka suudab sammu pidada.
Docker-compose on sellise mastaapsuse jaoks ideaalne partner. Selle asemel, et käitada Kafka maaklereid erinevatel virtuaalseadmetel, pakendame selle ja kasutame Docker Compose'i, et automatiseerida juurutamine ja skaleerimine. Dockeri konteinerid on väga skaleeritavad nii ühes Dockeri hostis kui ka üle klastri, kui kasutame Docker Swarmi või Kuberneteset. Seega on mõttekas seda kasutada, et Kafka oleks skaleeritav.
Alustame ühe maakleri eksemplarist. Looge kataloog nimega apache-kafka ja selle sees looge oma dokk-komponeerimine.yml.
$ mkdir apache-kafka$ cd apache-kafka
$ vim dokk-komponeeri.yml
Järgmine sisu pannakse teie dokk-komponeerimisse.yml-fail:
versioon: '3'teenused:
loomaaiatalitaja:
pilt: wurstmeister / loomaaednik
kafka:
pilt: wurstmeister / kafka
sadamad:
- "9092: 9092"
keskkond:
KAFKA_ADVERTISED_HOST_NAME: kohalik host
KAFKA_ZOOKEEPER_CONNECT: loomaaednik: 2181
Kui olete ülaltoodud sisu oma kirjutusfaili salvestanud, käivitage samast kataloogist:
$ docker-compose up -dOlgu, mida me siis siin tegime?
Docker-Compose'i mõistmine.yml
Koostamine käivitab kaks yml-failis loetletud teenust. Vaatame faili natuke tähelepanelikult. Esimene pilt on zookeeper, mida Kafka nõuab nii erinevate maaklerite, võrgu topoloogia kui ka muu teabe sünkroonimiseks. Kuna nii zookeeperi kui ka kafka teenused saavad olema osa samast sildvõrgust (see luuakse siis, kui käivitame docker-compose'i), ei pea me ühtegi porti paljastama. Kafka maakler saab rääkida loomaaiapidajaga ja see on kõik, mida loomaaednik vajab.
Teine teenus on kafka ise ja meil on lihtsalt üks eksemplar, see tähendab üks maakler. Ideaalis võiksite Kafka hajutatud arhitektuuri kasutamiseks kasutada mitut maaklerit. Teenus kuulab porti 9092, mis on kaardistatud Dockeri hosti samale pordinumbrile ja nii suhtleb teenus välismaailmaga.
Teises teenuses on ka paar keskkonnamuutujat. Esiteks on KAFKA_ADVERTISED_HOST_NAME seatud localhostiks. See on aadress, kus Kafka töötab ning kust tootjad ja tarbijad selle leiavad. Veelkord, see peaks olema seatud localhostile, vaid pigem IP-aadressile või hostinimele, mille kaudu serveritele teie võrgus pääseb. Teine on teie loomaaedniku teenuse hostinimi ja pordinumber. Kuna me panime zookeeper-teenusele nimeks ... noh, see on see, mida hostinimi saab, mainitud dockeri silla võrgus.
Lihtsa sõnumivoo käitamine
Selleks, et Kafka tööle asuks, peame selle sisse looma teema. Tootjakliendid saavad seejärel avaldada nimetatud teemale andmevood (sõnumid) ja tarbijad saavad seda datavoogu lugeda, kui nad on selle konkreetse teema tellinud.
Selleks peame käivitama interaktiivse terminali Kafka konteineriga. Loetlege konteinerid kafka konteineri nime hankimiseks. Näiteks kannab antud juhul meie konteiner nime apache-kafka_kafka_1
$ dokkija psKafka konteineri nimega võime nüüd selle konteineri sisse kukkuda.
$ docker exec -it apache-kafka_kafka_1 bashbash-4.4 #
Avage kaks sellist erinevat terminali, et kasutada ühte tarbijana ja teist tootjat.
Tootja pool
Sisestage ühte viipasse (selles, mille valite produtsendiks) järgmised käsud:
## Uue teema nimega testbash-4.4 # kafka-teemat.sh --create - zookeeper zookeeper: 2181 - replikatsioonikordaja 1
--partitsioonid 1 - teemaline test
## Tootja käivitamiseks, kes avaldab andmevoo tavapärasest sisendist kafkani
bash-4.4 # kafka-konsooli-tootja.sh - maakleri nimekirja kohalik host: 9092 - teemaline test
>
Produtsent on nüüd valmis klaviatuurilt sisendeid võtma ja need avaldama.
Tarbija pool
Liikuge oma kafka konteineriga ühendatud teise terminali juurde. Järgmine käsk käivitab tarbija, kes toidab testiteemat:
$ kafka-konsool-tarbija.sh --bootstrap-server localhost: 9092 - teemaline testTagasi Produceri juurde
Nüüd saate kirjutada sõnumid uude viipasse ja iga kord, kui vajutate nuppu, trükitakse uus rida tarbija viipasse. Näiteks:
> See on teade.See teade edastatakse tarbijale Kafka kaudu ja näete seda tarbija viipas printides.
Reaalses maailmas seadistused
Nüüd on teil ülevaade sellest, kuidas Kafka häälestus töötab. Enda tarbeks peate määrama hostinime, mis pole kohalik host, teil on vaja mitu sellist maaklerit, et olla osa teie kafka klastrist, ja lõpuks peate looma tarbija- ja tootja kliendid.
Siin on mõned kasulikud lingid:
- Confluenti Pythoni klient
- Ametlik dokumentatsioon
- Kasulik demode loend
Loodan, et teil on Apache Kafkat uurides lõbus.


