Elasticsearchi andmebaas
Elasticsearch on üks populaarsemaid NoSQL-i andmebaase, mida kasutatakse tekstipõhiste andmete salvestamiseks ja otsimiseks. See põhineb Lucene'i indekseerimistehnoloogial ja võimaldab indekseeritud andmete põhjal otsida millisekundites.
Elasticsearchi veebisaidi põhjal on siin määratlus:
Elasticsearch on avatud lähtekoodiga hajutatud RESTful otsingu- ja analüüsimootor, mis on võimeline lahendama üha suuremat arvu juhtumeid.
Need olid mõned kõrgetasemelised sõnad Elasticsearchi kohta. Mõistkem siin mõistetest üksikasjalikult.
- Levitatakse: Elasticsearch jagab selles sisalduvad andmed mitmeks sõlmeks ja kasutab peremees-ori algoritm sisemiselt
- RAHULIK: Elasticsearch toetab andmebaasi päringuid REST API-de kaudu. See tähendab, et saame kasutada lihtsaid HTTP-kõnesid ja kasutada selliseid HTTP-meetodeid nagu GET, POST, PUT, DELETE jne. andmetele juurdepääsemiseks.
- Otsingu- ja analüüsimootor: ES toetab süsteemis käivitamiseks väga analüütilisi päringuid, mis võivad koosneda koondatud päringutest ja mitut tüüpi, näiteks struktureeritud, struktureerimata ja geopäringutest.
- Horisontaalselt skaleeritav: Selline kelmimine viitab olemasolevate klastrite lisamisele masinatele. See tähendab, et ES suudab oma klastris vastu võtta rohkem sõlme ja ei võimalda süsteemi nõutavaid täiendusi. Mõõtmemõistete mõistmiseks vaadake allolevat pilti:
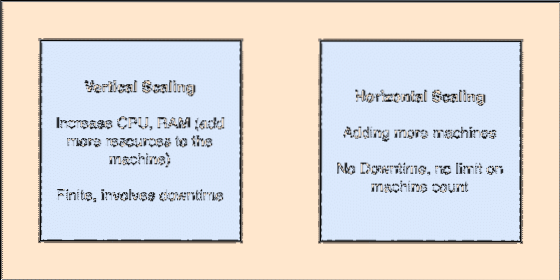
Vertikaalne ja horisontaalne scailing
Elasticsearchi andmebaasiga alustamine
Elasticsearchi kasutamise alustamiseks peab see olema masinasse installitud. Selleks lugege artiklit Installi otsimine Ubuntu.
Veenduge, et teil oleks aktiivne ElasticSearchi install, kui soovite proovida näiteid, mida me hiljem tunnis esitame.
Elasticsearch: mõisted ja komponendid
Selles jaotises näeme, millised komponendid ja mõisted asuvad Elasticsearchi südames. Nende mõistete mõistmine on oluline, et mõista, kuidas ES töötab:
- Kobar: Klaster on serverite (sõlmede) kogu, mis hoiab andmeid. Andmed jagatakse mitme sõlme vahel, nii et neid saab kopeerida ja ES Serveriga ei juhtu üksik tõrke (SPoF). Klastri vaikenimi on elasticsearch. Iga klastri sõlm ühendub klastriga URL-i ja klastri nimega, seega on oluline hoida see nimi selge ja selge.
- Sõlm: Sõlmeseade on osa serverist ja seda nimetatakse ühtseks masinaks. See salvestab andmeid ning pakub indekseerimise ja otsimise võimalusi koos teiste sõlmedega klastrisse.
Horisontaalse skaleerimise kontseptsiooni tõttu saame virtuaalselt lisada ES-klastrisse lõpmatu arvu sõlme, et anda sellele palju rohkem tugevust ja indekseerimisvõimalusi.
- Indeks: Indeks on mõnevõrra sarnaste omadustega dokumendikogu. Indeks on üsna sarnane andmebaasile SQL-põhises keskkonnas.
- Tüüp: Tüüpi kasutatakse andmete eraldamiseks sama indeksi vahel. Näiteks võib kliendiandmebaasil / registril olla mitut tüüpi, näiteks kasutaja, maksetüüp jne.
Pange tähele, et tüübid on vananenud versioonist ES v6.0.0 edasi. Loe siit, miks seda tehti.
- Dokument: Dokumendid on andmeid esitava üksuse madalaim tase. Kujutage seda ette nagu teie andmeid sisaldav JSON-objekt. Indeksis on võimalik indekseerida nii palju dokumente.
Otsingu tüübid Elasticsearchis
Elasticsearch on tuntud oma peaaegu reaalajas otsimise võimaluste ja paindlikkuse poolest, mida see pakub indekseeritavate ja otsitavate andmete tüübiga. Alustame uurimist, kuidas kasutada otsingut erinevat tüüpi andmetega.
- Struktureeritud otsing: seda tüüpi otsingut teostatakse andmetega, millel on eelnevalt määratletud vorming, näiteks kuupäevad, kellaajad ja numbrid. Eelnevalt määratletud vorminguga kaasneb paindlikkus tavaliste toimingute, näiteks väärtuste võrdlemise vahemikus, vahemikus. Huvitav, ka tekstiandmeid saab struktureerida. See võib juhtuda, kui väljal on kindel arv väärtusi. Näiteks võib andmebaaside nimi olla MySQL, MongoDB, Elasticsearch, Neo4J jne. Struktureeritud otsingu korral on meie vastatavatele päringutele vastus jah või ei.
- Täistekstotsing: seda tüüpi otsing sõltub kahest olulisest tegurist, Asjakohasus ja Analüüs. Asjakohasuse abil määrame tulemuste dokumentide skoori määratlemisega, kui hästi mõned andmed päringuga sobivad. Selle skoori annab ES ise. Analüüs viitab teksti jagamisele normaliseeritud märkideks, et luua tagurpidi register.
- Mitmeväline otsing: kuna ES-is talletatud andmetel suureneb pidevalt analüütiliste päringute arv, ei puutu me tavaliselt kokku lihtsalt vaste päringutega. Nõuded on kasvanud mitmel väljal ulatuvate päringute käitamiseks, mille andmebaas ise on meile tagastanud järjestatud andmete loendi. Nii saavad andmed lõppkasutaja jaoks olla palju tõhusamal viisil.
- Proimity Matching: Päringud on tänapäeval palju enamat kui lihtsalt tuvastada, kas mõned tekstiandmed sisaldavad teist stringi või mitte. See seisneb andmete vahelise seose loomises, et neid saaks skoorida ja sobitada andmete sobitamise kontekstiga. Näiteks:
- Pall tabas Johni
- John lõi palli
- John ostis uue Palli, mis tabas Jaeni aeda
Sobivuspäring leiab otsimisel kõik kolm dokumenti Pall tabas. Läheduseotsing võib meile öelda, kui kaugel need kaks sõna esinevad samal real või lõigus, mille tõttu need vastasid.
- Osaline sobitamine: sageli peame käivitama osalise vaste päringud. Osaline sobitamine võimaldab meil käivitada osaliselt vastavaid päringuid. Selle visualiseerimiseks vaatame sarnaseid SQL-põhiseid päringuid:
SQL-päringud: osaline sobitamine
WHERE nimi LIKE "% john%"
JA nimetage LIKE "% red%"
JA nimeta NAGU "% aed%"Mõnel juhul peame käivitama ainult osalised vastepäringud isegi siis, kui neid võib pidada jõhkrateks tehnikateks.
Integreerimine Kibanaga
Kui tegemist on analüüsimootoriga, siis peame tavaliselt käitama analüüsipäringuid äriteabe (BI) domeenis. Ärianalüütikute või andmeanalüütikute osas ei oleks õiglane eeldada, et inimesed teavad programmeerimiskeelt, kui nad tahavad visualiseerida ES klastris olevaid andmeid. Selle probleemi lahendab Kibana. Kibana pakub BI-le nii palju eeliseid, et inimesed saavad suurepärase, kohandatava juhtpaneeliga andmeid visualiseerida ja andmeid inaktiivselt näha. Vaatame siin mõningaid selle eeliseid.
Interaktiivsed graafikud
Kibana keskmes on sellised interaktiivsed graafikud: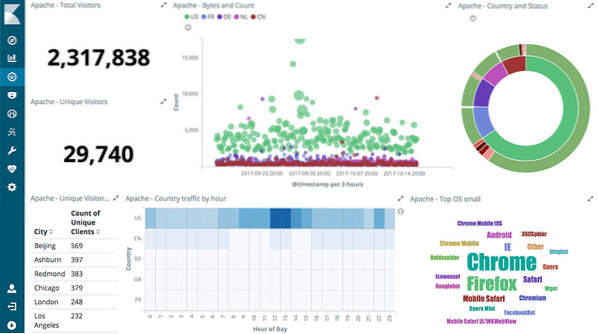
Kibana on varustatud erinevat tüüpi diagrammidega nagu sektordiagrammid, päikesepursked, histogrammid ja palju muud, mis kasutab ES-i täielikke liitmisvõimalusi.
Kaardistamise tugi
Kibana toetab ka täielikku geograafilist liitmist, mis võimaldab meil oma andmeid geograafiliselt kaardistada. Eks see ole lahe?!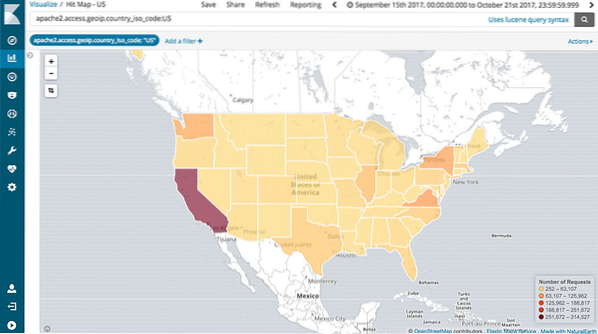
Eelkoostatud liitmised ja filtrid
Eelnevalt kokku pandud agregaatide ja filtrite abil on võimalik Kibana juhtpaneelil sõna otseses mõttes killustada, kukutada ja käivitada väga optimeeritud päringuid. Vaid mõne hiireklõpsuga on võimalik käivitada kokkuvõtlikud päringud ja esitada tulemusi interaktiivsete diagrammide kujul.
Armatuurlaudade lihtne levitamine
Kibana abil on juhtpaneele ka hõlpsasti palju laiemale publikule jagada ilma juhtpaneeli režiimi Ainult armatuurlaud abil muutmata. Saame hõlpsalt armatuurlaudu sisestada oma sisemisse vikisse või veebilehtedele.
Esiletõstetud pildid, mis on tehtud Kibana toote lehelt.
Elasticsearchi kasutamine
Eksemplari üksikasjade ja klastri teabe nägemiseks käivitage järgmine käsk: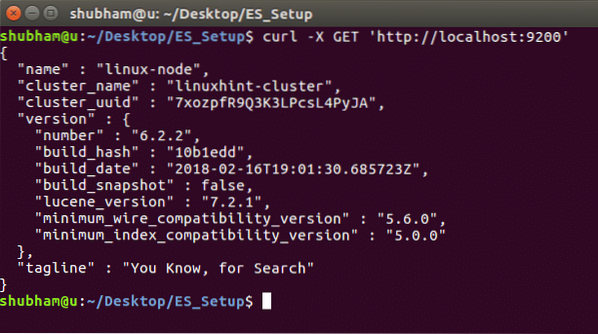
Nüüd võime proovida sisestada mõned andmed ES-i järgmise käsu abil:
Andmete sisestamine
lokkima \-X POSTITAMINE 'http: // localhost: 9200 / linuxhint / hello / 1' \
-H 'Sisutüüp: application / json' \
-d '"nimi": "LinuxHint"' \
Selle käsuga saame tagasi:
Proovime kohe andmeid hankida:
Andmete hankimine
curl -X GET 'http: // localhost: 9200 / linuxhint / tere / 1'Selle käsu käivitamisel saame järgmise väljundi:
Järeldus
Selles tunnis vaatasime, kuidas saaksime hakata kasutama ElasticSearchi, mis on suurepärane Analyticsi mootor ja pakub suurepärast tuge ka peaaegu reaalajas toimuva vabatekstiotsingu jaoks.