Tesseract: tasuta OCR-lahendus
Sissejuhatus
Tessereactit peetakse üheks parimaks saadaolevaks OCR-lahenduseks. Alates 2006. aastast on seda sponsoreerinud Google, varem töötas selle välja Hewlett Packard C- ja C ++ -s aastatel 1985–1998. Süsteem suudab tuvastada ühtlast käekirja, saab õppida täpsuse suurendamist ning on turul üks kõige arenenumaid ja terviklikumaid.
See võidab hõlpsalt kommertskonkurente nagu ABBY, kui otsite OCR-ile tõsist lahendust, on Tesseract kõige täpsem, kuid ärge oodake massiivsete lahenduste jaoks: see kasutab protsessi kohta südamikku, mis tähendab 8-tuumalist protsessorit (hüperlõng aktsepteeritud) saab korraga töödelda 8 või 16 pilti.
Kui kasutasin Tesseractit, õnnestus meil hallata tuhandeid potentsiaalseid kliente, kes laadisid üles käsitsi kirjutatud sisu, tekstiga pilte jne. Kasutasime 48 põhiserverit, DatabaseByDesign ja seejärel AWS, meil ei olnud kunagi ressursiprobleeme.
Meil oli üleslaadija, mis tegi vahet tekstifailide, näiteks Microsoft Office'i või Open Office'i failide, ja piltide või skannitud dokumentide vahel. Üleslaadija määras teksti tuvastamise valdkonnas kõik, mida OCR- või PHP-skriptid tellimust töötlevad.
Tesseact on suurepärane lahendus, kuid enne selle üle mõtlemist peate teadma, et viimased Tesseract'i versioonid tõid suuri parandusi, mõned neist tähendavad rasket tööd. Kui koolitus võib kesta tunde või päevi, võib hiljutine Tesserct'i versioonide väljaõpe olla päevade, nädalate või isegi kuudega, kui otsite mitmekeelset OCR-lahendust.
Tesseract 4 installimine Debiani / Ubuntu:
apt-get install tesseract-ocrKui kasutate mõnda muud Linuxi jaotust, peate kopeerima viimase githubi hoidla versiooni ja kopeerima .koolitatudandmete fail tessdata (/ usr / share / tesseract-ocr / tessdata või / usr / share / tessdata).
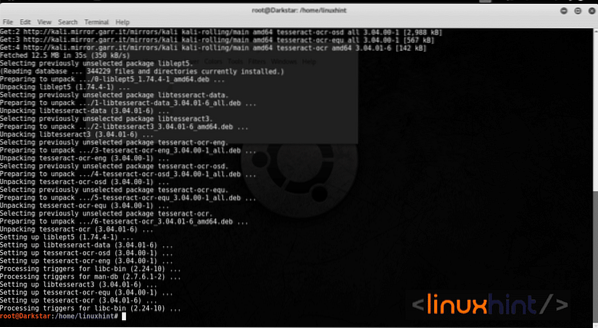
Vaikimisi installib Tesseract ingliskeelse paki, et installida täiendavaid keeli
apt-get install tesseract-ocr-LANGnäiteks heebrea lisamiseks:
apt-get install tesseract-ocr-hebKõiki keeli saate lisada käivitades:
apt-get install tesseract-ocr-all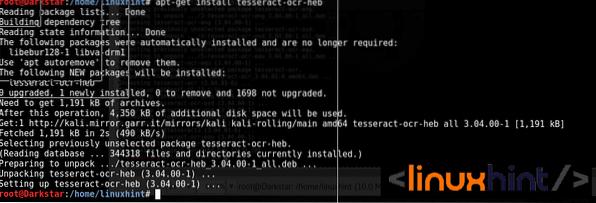
Selleks, et Tesseract korralikult töötaks, peame kasutama käsku „convert” (teisendamine nii pildivormingute vahel kui ka pildi suuruse muutmine, hägustamine, kärpimine, despeckle, tühjendamine, joonistamine, klappimine, liitumine, uuesti proovimine ja palju muud), pakub Imagemagick:
Võimaldab installida imagemagicki apt-getiga:
apt-get install imagemagickNüüd testime Tesseractit, leidke pilt, mis sisaldab teksti, ja käivitage:
tesseract [pildi_nimi] [väljundfaili nimi]Kui see on õigesti installitud, eraldab Tesseract pildilt teksti.
Kui töötasin Tesseractiga, oli meil vaja ainult dokumentide sõnade lugemist. Nagu iga teise programmi puhul saate ja peate seda koolitama, suudame ka Wordis määratleda mõned sümbolid, mida saab lugeda või mitte, kui loendada numbreid või mitte. sama ka Tesseractiga.
Samuti saame treenida selle tundlikkust konkreetsete piltide suhtes.
Tesseract optimeerimine:
Suuruse optimeerimine: Ametlike allikate andmetel on Tesseractis edukalt töödeldava pildi optimaalne suurus 300DPI. Selle DPI jõustamiseks peame mis tahes pildi töötlema parameetri -r abil. DPI suurendamine pikendab ka töötlemisaega.
Lehe pööramine: Kui skannimisel ei pööratud lehte õigesti ja see jääb 180 ° või 45 °, väheneb Tesseracti täpsus, saate selle Pythoni skripti abil pööramisprobleeme automaatselt tuvastada ja lahendada.
Piiri eemaldamine: Tesseract'i ametniku sõnul saab piire tähtedena ekslikult valida, eriti tumedad ääred ja seal, kus on erinev gradatsioon. Ääriste eemaldamine võib olla hea samm Tesseractiga maksimaalse täpsuse saavutamiseks.
Müra eemaldamine: Tesseractsi sõnul on müra pildi heleduse või värvi juhuslik variatsioon. Saame selle eemaldada binariseerimine samm, mis tähendab selle värvide polariseerimist.
Tesseracti koolitus:
Kuigi enamik õpetusi hõlmab ainult Tesseract'i installimist, võtan kokku, kuidas teie OCR-süsteemi koolitada, siit leiame õpetuse kõigi versioonide jaoks. Selles artiklis võtan kokku, kuidas treenida Tesseract 4, mis sisaldab uut „Närvivõrgupõhine tuvastamismootor, mis tagab eelmiste versioonidega võrreldes oluliselt suurema täpsuse (dokumendipiltidel), vastutasuks nõutava arvutusvõimsuse märkimisväärse kasvu eest. Keerulistes keeltes võib see tegelikult olla kiirem kui baas-Tesseract.”
Enne jätkamist peame installima täiendavaid teeke:
sudo apt-get install libicu-devsudo apt-get install libpango1.0-dev
sudo apt-get install libcairo2-dev
Ja installime treeningvahendid jooksvalt Tesseract'i kataloogi:
tegemateha koolitust
sudo tee koolitus-install
Tesseract'i ametliku wiki järgi on meil OCR-süsteemi koolitamiseks 3 võimalust:
- "Hea toon. Alustades olemasolevast koolitatud keelest, treenige oma konkreetseid täiendavaid andmeid. See võib töötada probleemide korral, mis on olemasolevatele treeningandmetele lähedased, kuid mingil peenel viisil erinevad, näiteks eriti ebatavaline font. Võib töötada isegi väikese koguse treeningandmetega.
- Lõigake ülemine kiht (või mõni meelevaldne arv kihte) võrgust välja ja koolitage uute andmete abil uus pealmine kiht. Kui peenhäälestus ei toimi, on see tõenäoliselt järgmine parim variant. Pealmise kihi lõikamine võib ikkagi töötada täiesti uue keele või skripti koolitamiseks, kui alustate kõige sarnasema välimusega skripti.
- Õppige nullist ümber. See on heidutav ülesanne, välja arvatud juhul, kui teil on oma probleemi jaoks ette nähtud väga esinduslik ja piisavalt mahukas koolitus. Kui ei, siis jõuate tõenäoliselt ülimugava võrguni, mis aitab treeningandmetel tõesti hästi, kuid mitte tegelikel andmetel.
Ehkki ülaltoodud valikud võivad tunduda erinevad, on koolitusetapid peale käsurea tegelikult peaaegu identsed, nii et seda on paralleelselt käivitamiseks vajaliku aja või riistvaraga suhteliselt lihtne kõiki võimalusi proovida.”
Selles õpetuses käivitame ainult tesstrain.sh skript, mis kutsub konkreetse keele koolitamiseks vajalikud programmid.
Kõigepealt laseb kloonida kõik meie / usr / share / tesseract-ocr failid:
gitkloon https: // github.com / tesseract-ocr / tesseract
Minge saidile / usr / share / tesseract-ocr / tesseract / training (Tesseracti vaikimisi installikataloog) ja käivitage:
$ ./ tesstrain.sh --lang heb --langdata_dir / usr / share / tesseract-ocr / langdata --tessdata_dir / usr / share / tesseract-ocr / tessdata
Muutke "heb" keeleks, mida soovite koolitada, ja muutke ka oma andmete teed.
Kataloogis / usr / share / tesseract-ocr / tesseract / koolitus leiate failispetsiifilise keele.sh kasulik lisada reeglid konkreetsete keelte jaoks.
Tõrkeotsing
Tesseract on minu jaoks parim OCR-lahendus, kuid hiljuti tegi see varasemate versioonidega võrreldes suuri muudatusi ja paljud kasutajad kurdavad muudatuste või asjade üle, mis enam ei tööta, ma ei muretseks, sest muudatused näivad andvat suurepäraseid tulemusi. Tesseract'i kogukond on väga aktiivne. Kui leiate probleeme tesseractiga, muutuge siin Tesseract'i kogukonna osaks.