Apache Spark on andmeanalüütika tööriist, mida saab kasutada HDFS, S3 või muude mälu andmeallikate andmete töötlemiseks. Selles postituses installime Apache Sparki Ubuntu 17-le.10 masin.
Ubuntu versioon
Selle juhendi jaoks kasutame Ubuntu versiooni 17.10 (GNU / Linux 4.13.0-38-üldine x86_64).
Apache Spark on osa Hadoopi suurandmete ökosüsteemist. Proovige installida Apache Hadoop ja tehke sellega näidisrakendus.
Olemasolevate pakettide värskendamine
Sparki installimise alustamiseks on vaja värskendada oma masinat uusimate saadaolevate tarkvarapakettidega. Saame seda teha:
sudo apt-get update && sudo apt-get -y dist-upgradeKuna Spark põhineb Java-l, peame selle oma arvutisse installima. Saame kasutada mis tahes Java versiooni Java 6 kohal. Siin kasutame Java 8:
sudo apt-get -y installib openjdk-8-jdk-peataSparki failide allalaadimine
Kõik vajalikud paketid on nüüd meie masinas olemas. Oleme valmis vajalikud Sparki TAR-failid alla laadima, et saaksime neid seadistama asuda ja Sparkiga ka näidisprogrammi käivitada.
Selles juhendis installime Spark v2.3.0 saadaval siin:
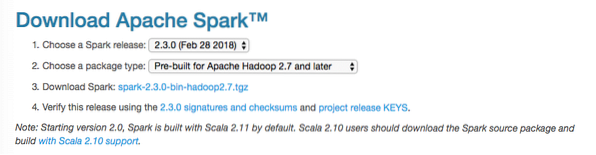
Sädeme allalaadimise leht
Selle käsuga laadige alla vastavad failid:
wget http: // www-us.apache.org / dist / säde / säde-2.3.0 / säde-2.3.0-bin-hadoop2.7.tgzSõltuvalt võrgu kiirusest võib see võtta kuni paar minutit, kuna fail on suur:
Apache Sparki allalaadimine
Nüüd, kui meil on TAR-fail alla laaditud, saame praegusest kataloogist välja tõmmata:
tõrva xvzf spark-2.3.0-bin-hadoop2.7.tgzArhiivi suure failisuuruse tõttu võtab see mõne sekundi täitmiseks:
Arhiivimata failid rakenduses Spark
Mis puutub Apache Sparki täiendamisse tulevikus, võib see Pathi värskenduste tõttu probleeme tekitada. Neid probleeme saab vältida, kui loote pehme lingi Sparkile. Käivitage see käsk pehme lingi loomiseks:
ln -säde-2.3.0-bin-hadoop2.7 sädeSädeme lisamine teele
Sparki skriptide käivitamiseks lisame selle nüüd teele. Selleks avage bashrc-fail:
vi ~ /.bashrcLisage need read rea lõppu .bashrc-fail, et tee saaks sisaldada käivitatava Spark-faili teed:
SPARK_HOME = / Linuxi vihje / sädeeksport PATH = $ SPARK_HOME / bin: $ PATH
Nüüd näeb fail välja järgmine:
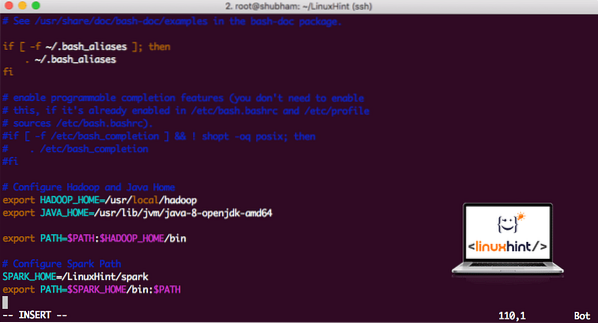
Sädeme lisamine teele
Nende muudatuste aktiveerimiseks käivitage bashrc-faili jaoks järgmine käsk:
allikas ~ /.bashrcSpark Shelli käivitamine
Nüüd, kui oleme otse sädemekataloogist väljaspool, käivitage aparki kesta avamiseks järgmine käsk:
./ säde / prügikast / sädemekarpNäeme, et Sparki kest on nüüd avatud:
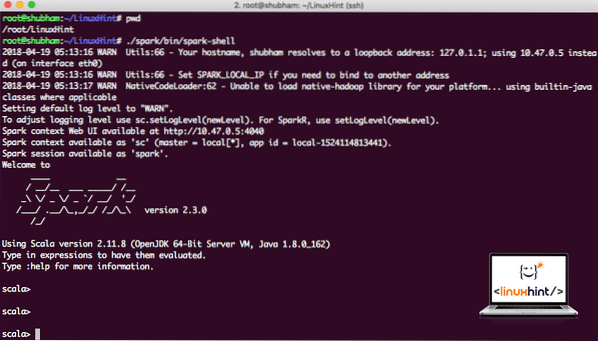
Sädemekesta käivitamine
Konsoolil näeme, et Spark on ka 404. pordis veebikonsooli avanud. Külastame seda:
Apache Sparki veebikonsool
Ehkki me töötame konsoolil endal, on veebikeskkond oluline koht, kuhu vaadata raskeid Spark-töid teostades, et teaksite, mis toimub igas teie teostatavas Spark-töös.
Sparki shelliversiooni kontrollige lihtsa käsuga:
sc.versioonMe saame tagasi midagi sellist:
res0: string = 2.3.0Scala abil Sparki rakenduse näidise tegemine
Nüüd teeme Apache Sparkiga Word Counteri rakenduse näidise. Selleks laadige kõigepealt tekstifail Sparki kesta Sparki konteksti:
scala> var Andmed = sc.textFile ("/ root / LinuxHint / spark / README.md ")Andmed: org.apache.säde.rdd.RDD [string] = / juur / LinuxHint / säde / LUGEMINE.md MapPartitionsRDD [1] tekstifailis aadressil: 24
scala>
Nüüd tuleb failis olev tekst jagada märgideks, mida Spark saab hallata:
scala> var tokens = Andmed.flatMap (s => s.split (""))märgid: org.apache.säde.rdd.RDD [String] = MapPartitionsRDD [2] korterikaardil: 25
scala>
Initsialiseerige nüüd iga sõna arv 1:
scala> var tokens_1 = märgid.kaart (s => (s, 1))märgid_1: org.apache.säde.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] kaardil: 25
scala>
Lõpuks arvutage faili iga sõna sagedus:
var sum_each = märgid_1.reducByKey ((a, b) => a + b)Aeg vaadata programmi väljundit. Koguge märgid ja nende loendused:
scala> sum_each.koguma ()res1: Massiiv [(String, Int)] = Massiiv ((pakett, 1), (For, 3), (Programs, 1), (töötlemine.,1), (Sest, 1), (The, 1), (lehekülg] (http: // säde.apache.org / dokumentatsioon.HTML).,1), (klaster.,1), (selle, 1), ([käivita, 1), (kui, 1), (API-d, 1), (on, 1), (proovige, 1), (arvutus, 1), (läbi, 1 ), (mitu, 1), (see, 2), (graafik, 1), (taru, 2), (ladustamine, 1), (["täpsustav, 1), (kuni, 2), (" lõng " , 1), (Üks kord, 1), (["Kasulik, 1), (eelista, 1), (SparkPi, 2), (mootor, 1), (versioon, 1), (fail, 1), (dokumentatsioon ,, 1), (töötlemine ,, 1), (the, 24), (on, 1), (süsteemid.,1), (paramid, 1), (mitte, 1), (erinev, 1), (viide, 2), (interaktiivne, 2), (R, 1), (antud.,1), (kui, 4), (järk, 4), (kui, 1), (olema, 2), (Testid, 1), (Apache, 1), (lõime, 1), (programmid, ) (sealhulgas 4), (./ bin / run-example, 2), (Säde.,1), (pakend.,1), (1000).loend (), 1), (versioonid, 1), (HDFS, 1), (D…
scala>
Suurepärane! Saime käivitada lihtsa Word Counteri näite, kasutades Scala programmeerimiskeelt koos tekstifailiga, mis on süsteemis juba olemas.
Järeldus
Selles tunnis vaatasime, kuidas saaksime Apache Sparki Ubuntu 17-s installida ja seda kasutama hakata.10 masinat ja käivitage sellel ka näidisrakendus.
Lisateavet Ubuntu-põhiste postituste kohta leiate siit.


