Andmetöötluse ja -analüüsi vältel aitavad histogrammid esindada sageduse jaotust ja saada hõlpsalt teadmisi. Vaatame mõningaid erinevaid meetodeid sageduse jaotuse saamiseks PostgreSQL-is. Histogrammi koostamiseks PostgreSQL-is saate kasutada mitmesuguseid PostgreSQL-histogrammi käske. Selgitame igaüht eraldi.
Esialgu veenduge, et arvutisüsteemi oleks installitud PostgreSQL käsurea kest ja pgAdmin4. Histogrammidega töötamise alustamiseks avage nüüd käsurea kest PostgreSQL. See palub teil kohe sisestada serveri nimi, millega soovite töötada. Vaikimisi on valitud 'localhost' server. Kui te järgmise valiku juurde hüpates ühe ei sisesta, jätkub see vaikimisi. Pärast seda palutakse teil sisestada andmebaasi nimi, pordi number ja kasutajanimi, millega töötada. Kui te seda ei esita, jätkub see vaikimisi. Nagu näete allpool olevalt pildilt, töötame "test" andmebaasi kallal. Lõpuks sisestage konkreetse kasutaja parool ja olge valmis.
Näide 01:
Meil peab olema andmebaasis mõned tabelid ja andmed, millega töötada. Nii oleme andmebaasi „testis” loonud tabeli „toode”, et salvestada erinevate toodete müügi andmed. Selles tabelis on kaks veergu. Üks on tellimuse kuupäev, et salvestada kuupäev, millal tellimus on tehtud, ja teine on „p_sold”, et salvestada kogu müügi arv konkreetsel kuupäeval. Selle tabeli loomiseks proovige oma käsk-shellis järgmist päringut.
>> CREATE TABLE toode (tellimuse_kuupäev DATE, p_müüdud INT);
Praegu on tabel tühi, nii et peame sellele mõned kirjed lisama. Niisiis, proovige selleks teha allpool käsk INSERT.
>> INSERT toote väärtusesse ('2021-03-01', 1250), ('2021-04-02', 555), ('2021-06-03', 500), ('2021-05-04' , 1000), ('2021-10-05', 890), ('2021-12-10', 1000), ('2021-01-06', 345), ('2021-11-07', 467 ), ('2021-02-08', 1250), ('2021-07-09', 789);
Nüüd saate kontrollida, kas tabelis on andmeid selles, kasutades allpool viidatud käsku SELECT.
>> VALI * FROM tootest;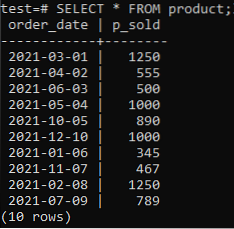
Põranda ja prügikasti kasutamine:
Kui teile meeldivad PostgreSQL histogrammi prügikastid, et pakkuda sarnaseid perioode (10-20, 20-30, 30-40 jne.), käivitage allpool käsk SQL. Hinname prügikasti numbrit allolevast avaldusest, jagades müügiväärtuse histogrammi prügikasti suurusega 10.
Selle lähenemise eeliseks on prügikastide dünaamiline muutmine andmete lisamisel, kustutamisel või muutmisel. Samuti lisatakse uute andmete jaoks täiendavad prügikastid ja / või kustutatakse prügikastid, kui nende arv jõuab nulli. Selle tulemusena saate PostgreSQL-is tõhusalt histogramme genereerida.
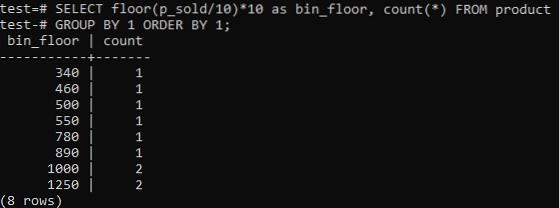
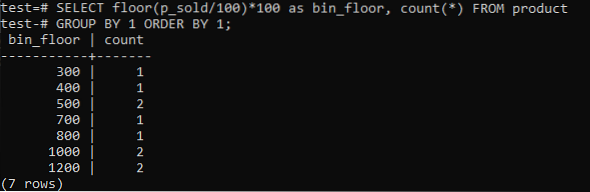
Vahetuspõrand (p_sold / 10) * 10 koos põrandaga (p_sold / 100) * 100 prügikasti suuruse suurendamiseks kuni 100.
Kasutades klauslit WHERE:
Ehitate sagedusjaotuse, kasutades CASE-deklaratsiooni, kui mõistate genereeritavate histogrammi prügikaste või kuidas histogrammimahuti suurused erinevad. PostgreSQL-i jaoks on allpool veel üks histogrammi lause:
>> VALI '100-300' AS_hinna vahel, COUNT (p_müüdud) KOGUM tootest, KUS p_müüdud 100–300 LIIDU VAHEL ) UNION (VALI '600-900', kui hind on vahemikus, COUNT (p_müüdud), KUI toode, KUI p_müüdud 600 JA 900 VAHEL JA 1300);Ja väljund näitab histogrammi sageduse jaotust veeru „p_sold” koguarvu väärtuste ja loenduse arvu kohta. Hinnad jäävad vahemikku 300-600 ja 900-1300, kokku on neid kokku 4. Müügivahemik 600–900 sai 2 loendust, vahemik 100–300 aga 0 müüki.
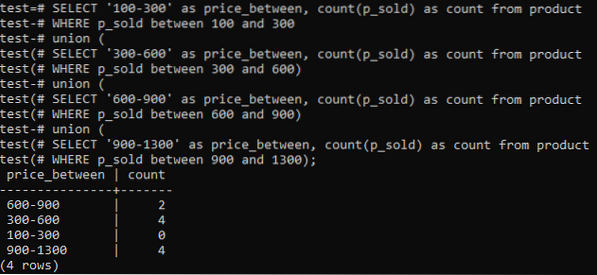
Näide 02:
Vaatame veel ühte näidet histogrammide illustreerimiseks PostgreSQL-is. Oleme loonud tabeli 'student', kasutades shellis allpool viidatud käsku. See tabel sisaldab teavet õpilaste kohta ja nende ebaõnnestunute arvu.
>> CREATE TABLE õpilane (std_id INT, fail_count INT);
Tabelis peavad olema mõned andmed. Seega oleme tabelisse "õpilane" andmete lisamiseks käivitanud käsu INSERT INTO:
>> INSERTTEERI õpilaste VÄÄRTUSTESSE (111, 30), (112, 60), (113, 90), (114, 3), (115, 120), (116, 150), (117, 180), (118 , 210), (119, 5), (120, 300), (121, 380), (122, 470), (123, 530), (124, 9), (125, 550), (126, 50) ), (127, 40), (128, 8);
Nüüd on tabel kuvatud väljundi kohta täidetud tohutu hulga andmetega. Sellel on juhuslikud väärtused std_id ja õpilaste ebaõnnestunud arv.
>> VALI * õpilasest;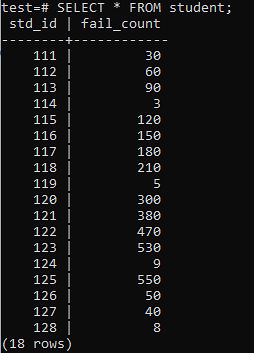
Kui proovite käivitada lihtsa päringu, et koguda ühe õpilase ebaõnnestumiste koguarv, on teil allpool nimetatud väljund. Väljund näitab iga õpilase ebaõnnestumiste arvu eraldi arvu veerus „std_id” kasutatavast meetodist „count”. See ei tundu eriti rahuldav.
>> SELECT fail_count, COUNT (std_id) õpilasgrupist 1 tellimuse järgi 1 järgi;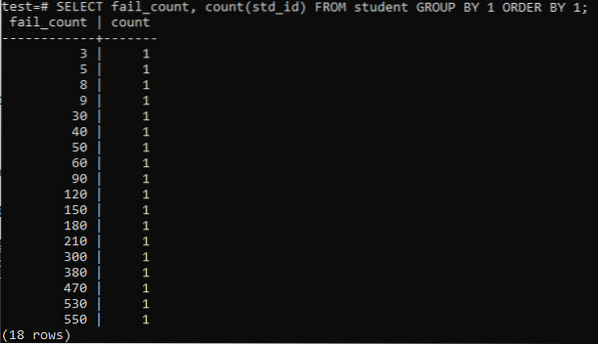
Sel juhul kasutame sarnaste perioodide või vahemike jaoks uuesti põranda meetodit. Niisiis, käivitage allpool nimetatud päring käsukooris. Päring jagab õpilaste fail_count 100-ga.00 ja seejärel rakendatakse põranda funktsiooni, et luua suurus 100. Seejärel võetakse kokku selles konkreetses vahemikus elavate õpilaste koguarv.
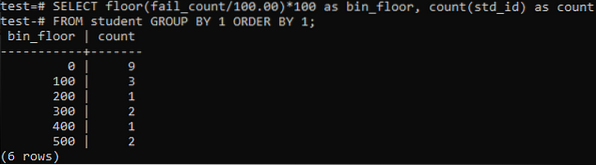
Järeldus:
Saame PostgreSQL-iga histogrammi genereerida, kasutades mis tahes eespool mainitud tehnikat, tuginedes nõuetele. Histogrammi ämbrid saate muuta igaks soovitud vahemikuks; ühtsed intervallid pole vajalikud. Kogu selle õpetuse käigus püüdsime selgitada parimaid näiteid, et selgitada oma kontseptsiooni seoses histogrammi loomisega PostgreSQL-is. Loodan, et järgides mõnda neist näidetest, saate PostgreSQL-is oma andmete jaoks mugavalt histogrammi luua.


