TextBlobi kasutamine tööstuses
Täpselt nii, nagu see kõlab, on TextBlob Pythoni pakett, et teha lihtsaid ja keerulisi tekstianalüüsi toiminguid tekstiandmetega nagu kõnesildistamine, nimisõnafraasi väljavõtmine, meeleolude analüüs, klassifitseerimine, tõlkimine ja palju muud. Kuigi TextBlobi jaoks on palju rohkem juhtumeid, mida võime kajastada teistes ajaveebides, hõlmab see tweetide analüüsi nende meeleolude kohta.
Analüüsielementidel on paljude stsenaariumide jaoks suurepärane praktiline kasutus:
- Geograafilises piirkonnas toimuvate poliitiliste valimiste ajal saab jälgida säutse ja muud sotsiaalmeedia tegevust, et saada hinnangulisi lahkumisküsitlusi ja tulemusi eelseisva valitsuse kohta
- Erinevad ettevõtted saavad sotsiaalmeedias kasutada tekstianalüüsi, et kiiresti tuvastada negatiivsed mõtted, mida antud piirkonnas sotsiaalmeedias levitatakse, et tuvastada probleemid ja need lahendada
- Mõni toode kasutab isegi säutse, et hinnata inimeste meditsiinilist suundumust nende sotsiaalsest tegevusest, näiteks seda, millist tüüpi säutse nad teevad, võib-olla käituvad nad enesetapuna jne.
TextBlobi kasutamise alustamine
Me teame, et tulite siia, et näha praktilist koodi, mis on seotud TextBlobi sentimentaalse analüsaatoriga. Seetõttu hoiame selle jaotise ülilühikese, et tutvustada uutele lugejatele TextBlobi. Lihtsalt enne alustamist tuleb märkida, et kasutame a virtuaalne keskkond selle õppetunni jaoks, mille tegime järgmise käsuga
python -m virtualenv tekstiplokkallikas textblob / bin / activate
Kui virtuaalne keskkond on aktiivne, saame installida TextBlobi teegi virtuaalsesse env-sse, et saaksime järgmiselt loodud näited täita:
pip install -U textblobKui olete ülaltoodud käsu käivitanud, pole see kõik. Samuti vajavad TextBlob juurdepääsu mõnele treeninguandmele, mille saab alla laadida järgmise käsuga:
python -m textblob.allalaadimiskorpusedNäete midagi sellist, laadides alla vajalikud andmed:
Nende näidete käitamiseks võite kasutada ka Anaconda, mis on lihtsam. Kui soovite selle oma arvutisse installida, vaadake õppetundi, mis kirjeldab artiklit „Kuidas Anaconda Pythoni installida Ubuntu 18.04 LTS ”ja jagage tagasisidet.
TextBlobi jaoks väga kiire näite kuvamiseks on siin näide otse selle dokumentatsioonist:
importige textblobist TextBlobtekst = ""
The Blobi nimeline ähvardus on mulle alati silma jäänud kui ülim film
koletis: tungimatult näljane, amööbilaadne mass
praktiliselt kõik kaitsemeetmed, mis on võimelised - nagu hukule määratud arst jahutavalt
kirjeldab seda - "liha assimileerimine kokkupuutel.
Snide võrdlused želatiiniga on neetud, see on kõige rohkem kontseptsioon
potentsiaalsete tagajärgede laastamine, erinevalt halli goo stsenaariumist
pakkusid tehnoloogiateoreetikud, kes kardavad
tehisintellekt jookseb ohjeldamatult.
""
plekk = TextBlob (tekst)
print (plekk.sildid)
print (plekk.nimisõnafraasid)
lause eest plekis.laused:
print (lause.tunne.polaarsus)
kämp.tõlkima (to = "es")
Kui käivitame ülaltoodud programmi, saame järgmised märgendisõnad ja lõpuks emotsioonid, mida näiteteksti kaks lauset demonstreerivad:
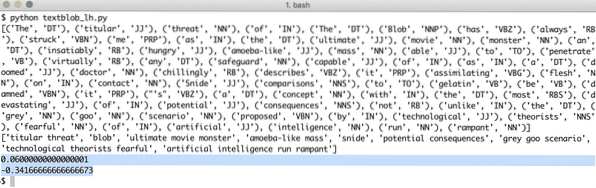
Märksõnad ja emotsioonid aitavad meil tuvastada peamised sõnad, mis tegelikult mõjutavad sentimentide arvutamist ja lause polaarsust. Seda seetõttu, et sõnade tähendus ja sentiment muutuvad nende kasutamise järjekorras, mistõttu tuleb seda kõike dünaamiliselt hoida.
Leksikonipõhine sentimentide analüüs
Iga sentimenti saab lihtsalt määratleda lauses kasutatud sõnade semantilise orientatsiooni ja intensiivsuse funktsioonina. Leksikonipõhise lähenemisviisi abil sõnade või lausete emotsioonide tuvastamiseks on iga sõna seotud hindega, mis kirjeldab emotsiooni, mida sõna eksponeerib (või vähemalt üritab eksponeerida). Tavaliselt on enamikul sõnadest nende leksikaalse skoori kohta eelnevalt määratletud sõnastik, kuid kui asi puudutab inimest, siis on alati mõeldud sarkasmi, nii et need sõnastikud ei ole sellised, millele saame 100% toetuda. WordStat Sentiment Dictionary sisaldab rohkem kui 9164 negatiivset ja 4847 positiivset sõnamustrit.
Lõpuks on meeleolude analüüsi tegemiseks (selle õppetundi raamest väljas) veel üks meetod, see on masinõppe tehnika, kuid me ei saa kasutada kõiki ML-algoritmi sõnu, kuna seisame kindlasti silmitsi probleemidega ülepakutades. Enne algoritmi koolitamist saame rakendada ühte funktsioonide valimise algoritmist, näiteks Chi ruut või vastastikune teave. Piirame ML-käsitluse arutelu ainult selle tekstiga.
Twitteri API kasutamine
Twitteris tweetide saamiseks külastage rakenduse arendaja kodulehte siin:
https: // arendaja.twitter.com / et / apps
Registreerige oma taotlus, täites selleks antud vormi:
Kui kõik märgid on vahekaardil „Võtmed ja märgid” saadaval, toimige järgmiselt
Twitteri API-st vajalike säutsude saamiseks saame kasutada võtmeid, kuid peame installima veel ühe Pythoni paketi, mis teeb meile Twitteri andmete hankimisel tugeva tõste:
pip paigaldada tweepyÜlaltoodud paketti kasutatakse kogu rasket suhtlust Twitteri API-ga lõpuleviimiseks. Tweepy eeliseks on see, et me ei pea kirjutama palju koodi, kui tahame oma rakendust Twitteri andmetega suhtlemiseks autentida ja see on automaatselt pakitud Tweepy paketi kaudu eksponeeritud väga lihtsasse API-sse. Saame ülaltoodud paketi oma programmi importida järgmiselt:
import tweepyPärast seda peame lihtsalt määrama sobivad muutujad, kus saame hoida arendajakonsoolilt saadud Twitteri võtmeid:
tarbija_võti = '[tarbija võti]'consumer_key_secret = '[tarbija_key_secret]'
access_token = '[access_token]'
access_token_secret = '[access_token_secret]'
Nüüd, kui määratlesime koodis Twitteri saladused, oleme lõpuks valmis Twitteriga ühendust looma, et säutsud vastu võtta ja nende üle kohut mõista, st neid analüüsida. Muidugi tuleb ühendus Twitteriga luua OAuthi standardi ja Tweepy pakett tuleb ühenduse loomiseks kasuks samuti:
twitter_auth = tweepy.OAuthHandler (tarbija võti, tarbija võtme saladus)Lõpuks vajame ühendust:
api = tweepy.API (twitter_auth)Kasutades API eksemplari, võime otsida Twitterist mis tahes teema, mille sellele edastame. See võib olla üks sõna või mitu sõna. Kuigi soovitame täpsuse huvides kasutada võimalikult vähe sõnu. Proovime siin ühte näidet:
pm_tweets = api.otsing ("India")Ülaltoodud otsing annab meile palju säutse, kuid me piirame tagasi saadetud säutsude arvu, et kõne ei võtaks liiga palju aega, kuna see tuleb hiljem ka TextBlobi paketiga töödelda:
pm_tweets = api.otsing ("India", arv = 10)Lõpuks saame printida iga säutsu teksti ja sellega seotud meeleolu:
tweetimiseks pm_tweets'is:print (piiksuma.tekst)
analüüs = TextBlob (säuts.tekst)
trükk (analüüs.tunne)
Kui ülaltoodud skript on käivitatud, hakkame saama mainitud päringu 10 viimast mainimist ja iga säutsu analüüsitakse meeleolu väärtuse osas. Siin on väljund, mille saime sama:

Pange tähele, et võite teha ka voogesituse meeleolude analüüsiboti ka TextBlobi ja Tweepy abil. Tweepy võimaldab luua veebipesa voogesituse ühenduse Twitteri API-ga ja võimaldab voogesitada Twitteri andmeid reaalajas.
Järeldus
Selles tunnis vaatasime suurepärast tekstianalüüsi paketti, mis võimaldab meil analüüsida tekstilisi tundeid ja palju muud. TextBlob on populaarne sellepärast, et see võimaldab meil lihtsalt töötada tekstiandmetega ilma keeruliste API-kõnede probleemideta. Twitteri andmete kasutamiseks integreerisime ka Tweepy. Saame sama paketiga ja koodis endas väga väheste muudatustega hõlpsasti kasutusviisi muuta.
Palun jagage oma tagasisidet õppetunni kohta Twitteris @linuxhint ja @sbmaggarwal (see olen mina!).


