Grepi on Linuxi süsteemides laialdaselt kasutatud mõne failiga töötamisel, mõne konkreetse mustri otsimisel ja paljudel teistel. Seekord kasutame käsku grep, et kuvada ridu enne ja pärast mõnes konkreetses failis kasutatud sobitatud märksõna. Sel eesmärgil kasutame kogu oma juhendaja juhendis märke „-A”, „-B” ja „-C”. Niisiis, paremaks mõistmiseks peate tegema iga sammu. Veenduge, et teil oleks Ubuntu 20.04 Linuxi süsteem installitud.
Esiteks peate grepiga töötamiseks avama oma Linuxi käsureaterminali. Praegu olete oma Ubuntu süsteemi kodukataloogis kohe pärast käsurea terminali avamist. Niisiis, proovige loetleda kõik failid ja kaustad oma Linuxi süsteemi kodukataloogis, kasutades allolevat käsku ls, ja saate kõik. Näete, et meil on loetletud mõned tekstifailid ja mõned kaustad.
ls
Näide 01: '-A' ja '-B' kasutamine
Ülaltoodud tekstifailidest vaatame mõnda neist ja proovime neile grep-käsku rakendada. Avame tekstifaili „üks.txt ”, kasutades kõigepealt populaarset käsku“ kass ”, nagu allpool:
$ kass üks.txt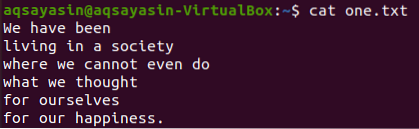
Kõigepealt näeme selles tekstifailis mõningaid konkreetseid sõnu, kasutades allolevat käsku grep. Otsime sõna "meie" tekstifailist "üks.txt ”, kasutades grep-käsku. Väljund näitab tekstifaili kahte rida, milles on “meie”.
$ grep me üks.txt
Nii et selles näites näitame mõnes tekstifailis ridu enne ja pärast konkreetset sõna vastet. Nii et sama tekstifaili „üks.txt "oleme sobitanud sõna" meie ", kuvades selle ees olevad 3 rida allpool. Lipp “-B” tähistab “Enne”. Väljundis kuvatakse ainult 2 rida enne konkreetset sõnalist rida, kuna failil pole konkreetse sõna rea ees rohkem ridu. See näitab ka neid ridu, milles on see konkreetne sõna.
$ grep -B 3 me üks.txt
Kasutame selles failis sama märksõna „meie”, et kuvada rea järel olevad 3 rida, millel on sõna „meie”. Lipp "-A" tähistab "Pärast". Väljund näitab jällegi ainult 2 rida, kuna sellel pole failis rohkem ridu.
$ grep -A 3 oleme üks.txt
Niisiis, kasutame sobitamiseks uut märksõna ja kuvame read või read enne ja pärast rida, milles see asub. Nii et oleme sobitamiseks kasutanud sõna “saab”. Ridanumbrid on sel juhul samad. 3 rida pärast sobitatud sõna "saab" on allpool kuvatud käsu grep abil.
$ grep -A 3 saab ühe.txt
Näete, et väljund näitab enne sobitatud sõna ridu, kasutades märksõna "saab". Seevastu näitab see ainult kahte rida enne sobitatud sõna rida, sest selle ees pole enam ridu.
$ grep -B 3 saab ühe.txt
Näide 02: '-A' ja '-B' kasutamine
Võtame veel ühe tekstifaili „kaks.txt ”kodukataloogist ja kuvage selle sisu, kasutades allpool olevat käsku“ kass ”.
$ kass kaks.txt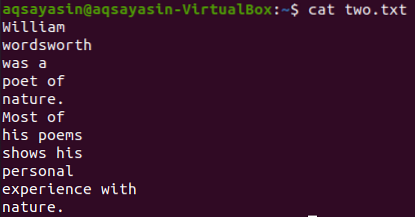
Kuvame 5 rida enne sõna “Enamik” failist “kaks.txt ”, kasutades käsku grep. Väljund näitab 5 rida, enne kui rida sisaldab konkreetset sõna.
$ grep -B 5 Enamik kaks.txt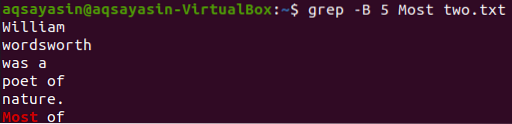
Grep-käsk näitab 5 rida pärast sõna „Enamik“ tekstifailist „kaks.txt ”on toodud allpool.
$ grep -A 5 Enamik kaks.txt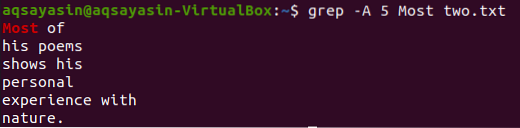
Muudame otsitavat märksõna. Sel korral sobitamiseks kasutame märksõna „of”. Kuvage 2 rida enne sõna „of” tekstifailist „two.txt ”saab kasutada alloleva käsu grep abil. Väljund näitab märksõna „of” kahte rida, kuna see tuleb failis kaks korda. Seega sisaldab väljund rohkem kui 2 rida.
$ grep -B 2 kahest.txt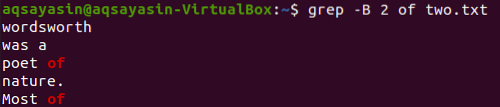
Nüüd kuvatakse 2 failirida „kaks.txt ”pärast rida, mis sisaldab märksõna“ of ”, saab teha alloleva käsu abil. Väljund kuvab jällegi rohkem kui 2 rida.
$ grep -A 2 kahest.txt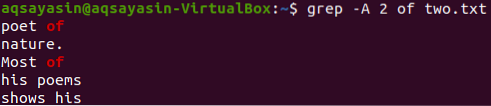
Näide 03: '-C' kasutamine
Ridade kuvamiseks sobitatud sõna ees ja järel on kasutatud teist lippu “-C”. Kuvame faili sisu „üks.txt ”, kasutades kassi käsku.
$ kass üks.txt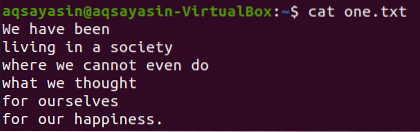
Valime sobitatava märksõnana “ühiskonna”. Allpool olev käsk grep kuvab 2 rida enne ja 2 rida pärast rida, mis sisaldab sõna "ühiskond". Väljund näitab ühte rida enne konkreetset sõnalist rida ja 2 rida pärast seda.
$ grep -C 2 seltskond üks.txt
Vaatame faili „kaks.txt ”, kasutades allpool olevat kassi käsku.
$ kass kaks.txt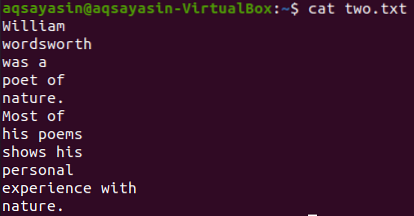
Selles illustratsioonis kasutame sobitamiseks märksõnana luuletusi. Niisiis, täitke selle jaoks järgmine käsk. Väljundis kuvatakse kaks rida enne ja kaks rida pärast sobitatud sõna.
$ grep -C 2 luuletust kaks.txt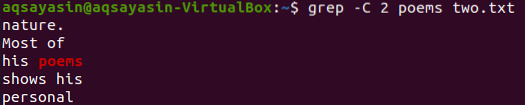
Kasutame veel ühte märksõna failist „kaks.txt ”tuleb sobitada. Tarbime seekord märksõnana loodust. Niisiis, proovige allolevat käsku, kui kasutate märgistusel „-C” märksõnaga „loodus” failist „kaks”.txt ”. Seekord on väljundis rohkem kui kaks rida. Kuna fail sisaldab sõna "loodus" rohkem kui üks kord, on see selle põhjus. Esimesel kohal oleval märksõnal “loodus” on kaks rida enne ja kaks rida pärast seda. Kui teine vastas samale märksõnale, on loodusel enne seda kaks rida, kuid selle järel pole ühtegi rida, kuna see asub faili viimasel real.
$ grep -C 2 luuletust kaks.txt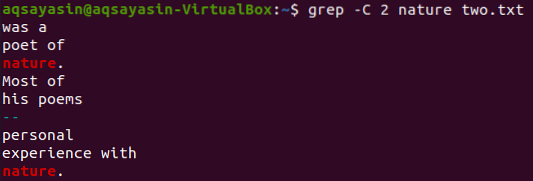
Järeldus
Grep-käsu kasutamisel oleme edukalt kuvanud ridu enne ja pärast konkreetset sõna.


