
Kui hakkasin töötama masinõppeprobleemidega, tunnen ma paanikat, millist algoritmi peaksin kasutama? Või kumba on lihtne rakendada? Kui olete nagu mina, võib see artikkel aidata teil teada saada tehisintellekti ja masinõppe algoritmide, meetodite või tehnikate kohta ootamatute või isegi oodatud probleemide lahendamiseks.
Masinõpe on nii võimas tehisintellektitehnika, mis võimaldab ülesannet tõhusalt täita, ilma et oleks vaja sõnaselgeid juhiseid. ML-mudel saab õppida oma andmetest ja kogemustest. Masinõpperakendused on automaatsed, tugevad ja dünaamilised. Tegelike probleemide selle dünaamilise olemuse lahendamiseks on välja töötatud mitu algoritmi. Üldiselt on masinõppe algoritme kolme tüüpi, näiteks juhendatud õppimine, järelevalveta õppimine ja täiendõpe.
Parimad tehisintellekti ja masinõppe algoritmid
Tehisintellekti või masinõppe projekti väljatöötamise üks peamisi ülesandeid on sobiva masinõppe tehnika või meetodi valimine. Kuna on olemas mitu algoritmi, on kõigil neist oma eelised ja kasulikkus. Allpool jutustame 20 masinõppe algoritmi nii algajatele kui ka professionaalidele. Niisiis, lähme vaatama.
1. Naiivne Bayes
Naiivne Bayesi klassifikaator on tõenäosuslik klassifikaator, mis põhineb Bayesi teoreemil, eeldades tunnuste sõltumatust. Need funktsioonid erinevad rakenduste kaupa. See on üks mugavaid masinõppemeetodeid algajatele harjutamiseks.
Naiivne Bayes on tingimusliku tõenäosuse mudel. Arvestades klassifitseeritavat probleeminstanssi, mida esindab vektor x = (xi … Xn) esindades mõnda n omadust (sõltumatud muutujad), määrab see praeguse eksemplari tõenäosused kõigi K potentsiaalsete tulemuste jaoks:
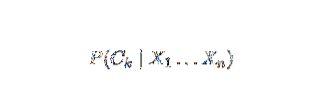 Ülaltoodud sõnastuse probleem seisneb selles, et kui funktsioonide arv n on märkimisväärne või kui element võib omandada suure hulga väärtusi, siis on sellise mudeli aluseks tõenäosustabelid. Seetõttu arendame mudeli ümber, et muuta see paremini jälgitavaks. Bayesi teoreemi kasutades võib tingliku tõenäosuse kirjutada järgmiselt,
Ülaltoodud sõnastuse probleem seisneb selles, et kui funktsioonide arv n on märkimisväärne või kui element võib omandada suure hulga väärtusi, siis on sellise mudeli aluseks tõenäosustabelid. Seetõttu arendame mudeli ümber, et muuta see paremini jälgitavaks. Bayesi teoreemi kasutades võib tingliku tõenäosuse kirjutada järgmiselt,
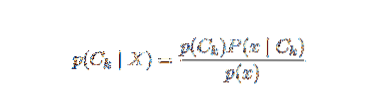
Bayesi tõenäosusterminoloogiat kasutades saab ülaltoodud võrrandi kirjutada järgmiselt:
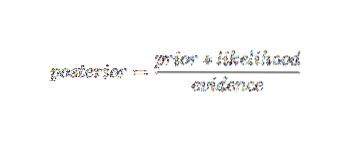
Seda tehisintellekti algoritmi kasutatakse teksti klassifitseerimisel, s.t.e., sentimentide analüüs, dokumentide kategoriseerimine, rämpsposti filtreerimine ja uudiste klassifikatsioon. See masinõppe tehnika toimib hästi, kui sisendandmed liigitatakse eelnevalt määratletud rühmadesse. Samuti nõuab see vähem andmeid kui logistiline regressioon. See edestab erinevates domeenides.
2. Toetage vektormasinat
Tugivektorimasin (SVM) on üks kõige laialdasemalt kasutatavaid juhendatud masinõppe algoritme teksti klassifikatsiooni valdkonnas. Seda meetodit kasutatakse ka regressiooni korral. Seda võib nimetada ka tugivektorivõrkudeks. Cortes & Vapnik töötasid selle meetodi välja binaarse klassifikatsiooni jaoks. Juhendatud õppemudel on masinõppe lähenemisviis, mis järeldab märgistatud treeningandmete väljundit.
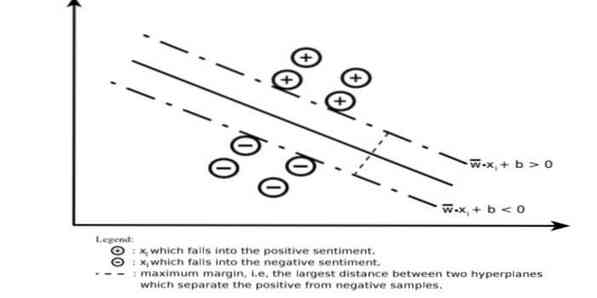
Tugivektorimasin konstrueerib hüpertasandi või hüperlennukite komplekti väga kõrgel või lõpmatu dimensiooniga alal. See arvutab lineaarse eralduspinna antud treeningkomplekti maksimaalse varuga.
Ainult sisendvektorite alamhulk mõjutab veerise valikut (joonisel ümardatud); selliseid vektoreid nimetatakse tugivektoriteks. Kui lineaarset eralduspinda pole olemas, näiteks mürarikaste andmete olemasolul, sobivad lõtku muutujaga SVM-ide algoritmid. See klassifikaator üritab andmeruumi jaotada lineaarsete või mittelineaarsete piiritluste abil erinevate klasside vahel.
SVM-i on laialdaselt kasutatud mustrite klassifitseerimise probleemide ja mittelineaarse regressiooni korral. Samuti on see üks parimaid tehnikaid teksti automaatse kategoriseerimise teostamiseks. Parim asi selle algoritmi juures on see, et see ei tee andmete kohta tugevaid oletusi.
Tugivektorimasina juurutamiseks: andmeteaduste raamatukogud Pythonis - SciKit Learn, PyML, SVMStruktuur Python, LIBSVM ja andmeteaduste raamatukogud R-Klaris, e1071.
3. Lineaarne regressioon
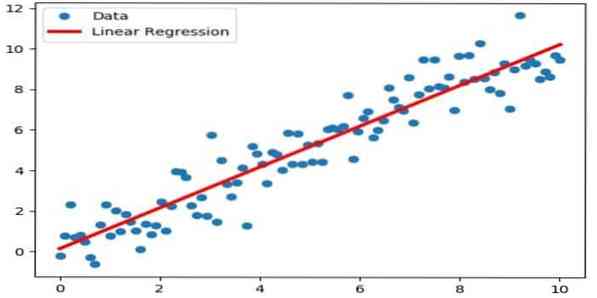
Lineaarne regressioon on otsene lähenemisviis, mida kasutatakse sõltuva muutuja ja ühe või mitme sõltumatu muutuja vahelise suhte modelleerimiseks. Kui on üks sõltumatu muutuja, siis nimetatakse seda lihtsaks lineaarseks regressiooniks. Kui saadaval on rohkem kui üks sõltumatu muutuja, nimetatakse seda mitmeks lineaarseks regressiooniks.
Seda valemit kasutatakse selliste tegelike väärtuste hindamiseks nagu kodude hind, kõnede arv, kogumüük pidevate muutujate põhjal. Siin luuakse suhe sõltumatute ja sõltuvate muutujate vahel, sobitades parima rea. Seda kõige paremini sobivat joont tuntakse regressioonijoonena ja seda esindab lineaarvõrrand
Y = a * X + b.
siin,
- Y - sõltuv muutuja
- a - kalle
- X - sõltumatu muutuja
- b - pealtkuulamine
Seda masinõppemeetodit on lihtne kasutada. See teostatakse kiiresti. Seda saab kasutada ettevõtluses müügi prognoosimiseks. Seda saab kasutada ka riskide hindamisel.
4. Logistiline regressioon
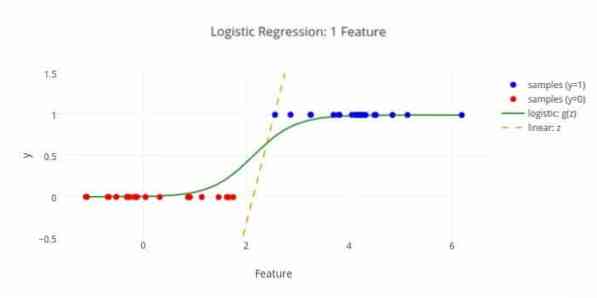
Siin on veel üks masinõppe algoritm - logistiline regressioon või logit regressioon, mida kasutatakse diskreetsete väärtuste (binaarväärtused nagu 0/1, jah / ei, tõene / väär) hindamiseks sõltumatu muutuja etteantud hulga põhjal. Selle algoritmi ülesanne on ennustada juhtumi tõenäosust, sobitades andmed logit-funktsioonile. Selle väljundväärtused jäävad vahemikku 0 kuni 1.
Valemit saab kasutada erinevates valdkondades, nagu masinõpe, teadusharu ja meditsiinivaldkond. Seda saab kasutada konkreetse haiguse tekkimise ohu ennustamiseks patsiendi täheldatud omaduste põhjal. Logistilist regressiooni saab kasutada selleks, et ennustada kliendi soovi osta toodet. Seda masinõppe tehnikat kasutatakse ilmaennustustes vihma tekkimise tõenäosuse ennustamiseks.
Logistilise regressiooni võib jagada kolme tüüpi -
- Binaarne logistiline regressioon
- Mitme nominaalne logistiline regressioon
- Järjestuslik logistiline regressioon
Logistiline taandareng pole nii keeruline. Samuti on see vastupidav. See saab hakkama mittelineaarsete efektidega. Kui treeningandmed on hõredad ja suure mõõtmetega, võib see ML-algoritm siiski üle sobida. See ei suuda ennustada pidevaid tulemusi.
5. K-lähim naaber (KNN)
K-lähim naaber (kNN) on klassifitseerimisel hästi tuntud statistiline lähenemisviis, mida on aastate jooksul laialdaselt uuritud ja mida on kategoriseerimisülesannetes varakult rakendatud. See toimib klassifitseerimis- ja regressiooniprobleemide mitteparameetrilise metoodikana.
See AI ja ML meetod on üsna lihtne. See määrab testdokumendi kategooria t selle põhjal, kui hääletatakse k dokumentide kogum, mis on vahemaale lähima t, tavaliselt Eukleidese kaugus. KNN-i klassifikaatori testdokumendi t jaoks antud oluline otsuse reegel on:
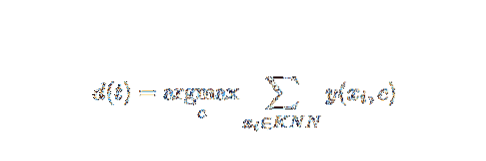
Kui y (xi, c) on koolitusdokumendi xi binaarne klassifikatsioonifunktsioon (mis tagastab väärtuse 1, kui xi on märgistatud tähisega c või 0 muul viisil), märgistab see reegel tähega t kategooriaga, mis annab k-s kõige rohkem hääli - lähim naabruskond.
Meid saab KNN-i kaardistada oma tegelikku ellu. Näiteks kui soovite teada saada mõnda inimest, kellest teil pole teavet, eelistaksite tõenäoliselt otsustada tema lähedaste sõprade ja seetõttu nende suhtlusringide osas, kus ta liigub, ja pääseda juurde tema teabele. See algoritm on arvutuslikult kallis.
6. K-tähendab
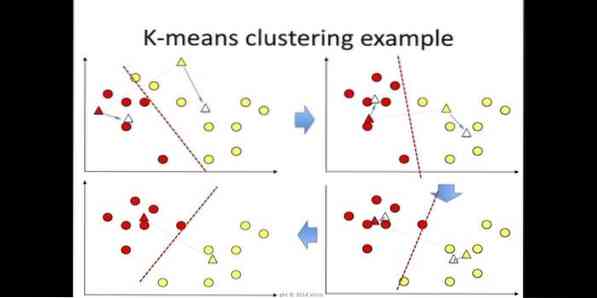
k-tähendab klastramine on järelevalveta õppimise meetod, millele on juurdepääs andmekaevanduses klastrianalüüsiks. Selle algoritmi eesmärk on jagada n vaatlust k klastriteks, kus iga vaatlus kuulub klastri lähimale keskmisele. Seda algoritmi kasutatakse turu segmenteerimisel, arvutinägemisel ja astronoomias paljude teiste valdkondade hulgas.
7. Otsustuspuu
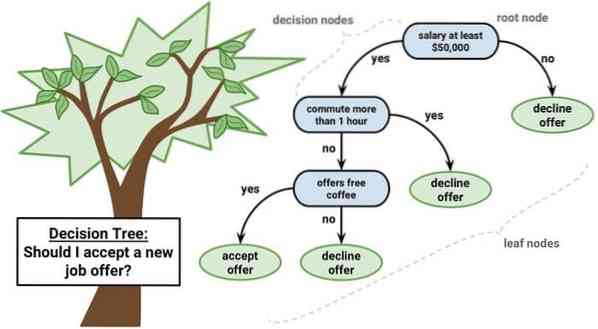
Otsustuspuu on otsuste toetamise tööriist, mis kasutab graafilist esitust, s.t.e., puulaadne graafik või otsuste mudel. Seda kasutatakse tavaliselt otsuste analüüsimisel ja populaarne tööriist masinõppes. Otsustuspuid kasutatakse operatsioonide uurimisel ja operatsioonide juhtimisel.
Sellel on vooskeemilaadne struktuur, milles iga sisesõlm tähistab atribuudi „testi”, iga haru näitab testi tulemust ja iga lehesõlm tähistab klassi silti. Teekond juurest leheni on tuntud kui klassifitseerimisreeglid. See koosneb kolme tüüpi sõlmedest:
- Otsusesõlmed: tavaliselt esindatud ruutudega,
- Võimaluse sõlmed: tavaliselt esindatud ringidega,
- Lõppsõlmed: tavaliselt kolmnurgad.
Otsustuspuud on lihtne mõista ja tõlgendada. See kasutab valge kasti mudelit. Samuti saab seda kombineerida teiste otsustamisvõtetega.
8. Juhuslik mets
Juhuslik mets on populaarne ansamblite õppimise tehnika, mis töötab treeningu ajal paljude otsustuspuude ehitamisel ja väljastab kategooria, mis on iga puu kategooriate (klassifikatsioon) või keskmise prognoosi (regressiooni) režiim.
Selle masinõppe algoritmi käitusaeg on kiire ja see suudab töötada tasakaalustamata ja puuduvate andmetega. Kuid kui me seda regressiooniks kasutasime, ei saa see treeningandmetes ette näha, ja see võib andmeid liiga palju sobitada.
9. KORV
Klassifikatsiooni- ja regressioonipuu (CART) on ühte tüüpi otsustuspuu. Otsustuspuu töötab rekursiivse jaotamismeetodina ja CART jagab kõik sisendsõlmed kaheks alamsõlmeks. Otsustuspuu igal tasandil tuvastab algoritm tingimuse - millist muutujat ja taset saab kasutada sisendsõlme jagamiseks kaheks alamsõlmeks.
CART-i algoritmi sammud on toodud allpool:
- Võtke sisendandmed
- Parim Split
- Parim muutuja
- Jagage sisendandmed vasakusse ja paremasse sõlme
- Jätkake 2.-4
- Otsustuspuu pügamine
10. Apriori masinõppe algoritm

Apriori algoritm on kategoriseerimise algoritm. Seda masinõppe tehnikat kasutatakse suurte andmehulkade sorteerimiseks. Seda saab kasutada ka suhete arengu ja kategooriate ülesehituse jälgimiseks. See algoritm on järelevalveta õppemeetod, mis genereerib antud andmekogumist assotsiatsioonireeglid.
Apriori masinõppe algoritm töötab järgmiselt:
- Kui üksusekomplekt toimub sageli, siis juhtuvad sageli ka kõik üksuste komplektid.
- Kui üksusekomplekti esineb harva, siis esineb harva ka üksuse komplekti kõiki ülekoormusi.
Seda ML-algoritmi kasutatakse paljudes rakendustes, näiteks ravimite kõrvaltoimete tuvastamiseks, turukorvi analüüsiks ja automaatse täitmise rakendusteks. Selle rakendamine on lihtne.
11. Põhikomponentide analüüs (PCA)
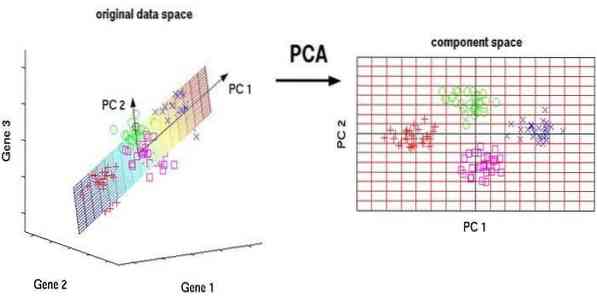
Põhikomponentide analüüs (PCA) on järelevalveta algoritm. Uued funktsioonid on ristkülikud, see tähendab, et need pole omavahel seotud. Enne PCA-d peaksite oma andmekogumi alati normaliseerima, kuna teisendus sõltub skaalast. Kui te seda ei tee, domineerivad uutes põhikomponentides kõige olulisemal skaalal olevad omadused.
PCA on mitmekülgne tehnika. See algoritm on vaevatu ja seda on lihtne rakendada. Seda saab kasutada piltide töötlemisel.
12. CatBoost
CatBoost on avatud lähtekoodiga masinõppe algoritm, mis pärineb Yandexist. Nimi 'CatBoost' tuleneb kahest sõnast 'Kategooria' ja 'Boosting.„Seda saab kombineerida sügavate õpperaamistikega, s.t.e., Google'i TensorFlow ja Apple'i Core ML. CatBoost saab mitme probleemi lahendamiseks töötada arvukate andmetüüpidega.
13. Iteratiivne dihotomeer 3 (ID3)
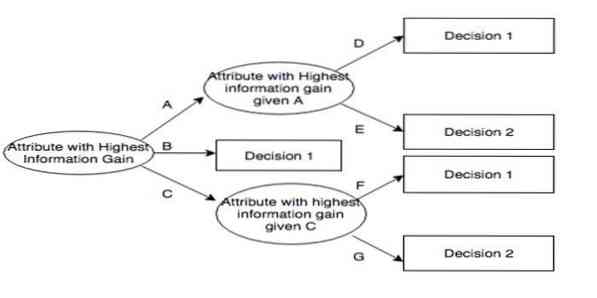
Iteratiivne dihhotomeer 3 (ID3) on otsustuspuu õppimise algoritmireegel, mille esitas Ross Quinlan ja mida kasutatakse andmekogumist otsustuspuu pakkumiseks. See on C4 eelkäija.5 algoritmiprogrammi ning seda kasutatakse masinõppe ja keelelise suhtlemise protsesside valdkonnas.
ID3 võib treeningandmetele üle sobida. Seda algoritmireeglit on pidevate andmete korral raskem kasutada. See ei taga optimaalset lahendust.
14. Hierarhiline klasterdamine
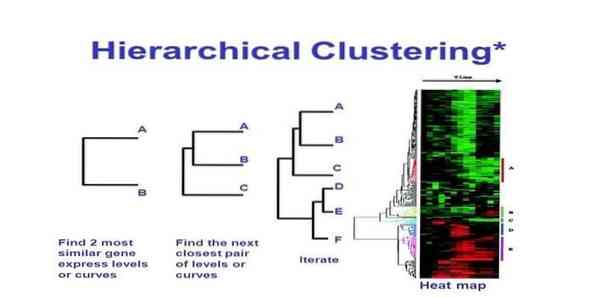
Hierarhiline klasterdamine on klasteranalüüsi viis. Hierarhilises klastris töötatakse andmete illustreerimiseks välja klastripuu (dendrogramm). Hierarhilises klastris lingib iga rühm (sõlm) kahe või enama järeltulija rühmaga. Iga klastripuu sõlm sisaldab sarnaseid andmeid. Sõlmed grupeeruvad graafikul teiste sarnaste sõlmede kõrval.
Algoritm
Selle masinõppemeetodi võib jagada kaheks mudeliks - põhjani või ülevalt alla:
Alt üles (hierarhiline aglomeratiivne klasterdamine, HAC)
- Selle masinõppe tehnika alguses võtke iga dokument ühe klastrina.
- Uues klastris liitis kaks üksust korraga. See, kuidas kombineerimised ühinevad, hõlmab arvutatud erinevust iga ühendatud paari ja seega ka alternatiivsete proovide vahel. Selleks on palju võimalusi. Mõned neist on:
a. Täielik sidumine: Kaugeima paari sarnasus. Üks piirang on see, et kõrvalised väärtused võivad põhjustada lähedaste rühmade liitmise optimaalsest hiljem.
b. Ühe lülitusega: Lähima paari sarnasus. See võib põhjustada enneaegset ühinemist, ehkki need rühmad on üsna erinevad.
c. Grupi keskmine: sarnasus rühmade vahel.
d. Tsentroidi sarnasus: iga iteratsioon ühendab klastrid eesmise sarnase keskpunktiga.
- Kuni kõik üksused ühinevad üheks klastriks, jätkub sidumisprotsess.
Ülalt alla (jaotav klastrite moodustamine)
- Andmed algavad kombineeritud klastrist.
- Klaster jaguneb teatud sarnasuse järgi kaheks erinevaks osaks.
- Klastrid jagunevad ikka ja jälle kaheks, kuni klastrid sisaldavad ainult ühte andmepunkti.
15. Tagasi paljundamine
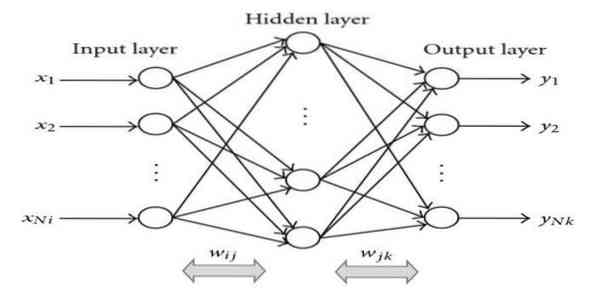
Tagasi levitamine on juhendatud õppealgoritm. See ML-algoritm pärineb ANN (kunstlikud närvivõrgud) piirkonnast. See võrk on mitmekihiline edasivõrk. Selle tehnika eesmärk on kujundada antud funktsioon, muutes sisendsignaalide sisemassid soovitud väljundsignaali saamiseks. Seda saab kasutada liigitamiseks ja regressiooniks.

Tagasi levimise algoritmil on mõned eelised, st.e., seda on lihtne rakendada. Algoritmis kasutatud matemaatilist valemit saab rakendada mis tahes võrgus. Kui kaal on väike, võib arvutusaega lühendada.
Tagasi levimise algoritmil on mõningaid puudusi, näiteks see võib tundlik olla mürarikaste andmete ja kõrvalekallete suhtes. See on täielikult maatriksil põhinev lähenemine. Selle algoritmi tegelik jõudlus sõltub täielikult sisendandmetest. Väljund võib olla mitte arvuline.
16. AdaBoost
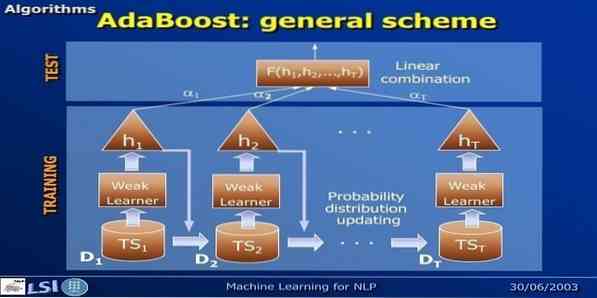
AdaBoost tähendab Adaptive Boosting, masinõppe meetodit, mida esindavad Yoav Freund ja Robert Schapire. See on meta-algoritm ja seda saab integreerida teiste õppimisalgoritmidega, et parandada nende jõudlust. Seda algoritmi on kiire ja lihtne kasutada. See töötab hästi suurte andmekogumitega.
17. Sügav õppimine
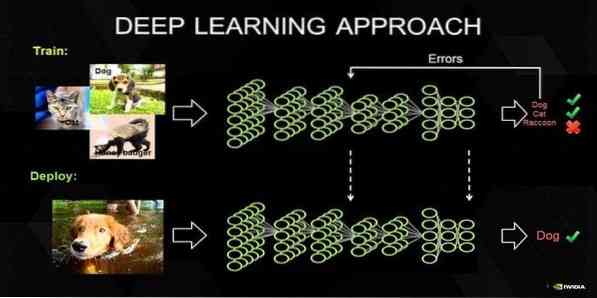
Sügav õppimine on kogum tehnikaid, mis on inspireeritud inimese aju mehhanismist. Kaks esmast sügavat õppimist, s.t.e., Konversioonnärvivõrke (CNN) ja korduvaid närvivõrke (RNN) kasutatakse teksti klassifitseerimisel. Sügavate õppimisalgoritmidega nagu Word2Vec või GloVe kasutatakse ka kõrgete vektorvormingute esitamiseks sõnu ja klassifikaatorite täpsuse parandamiseks, mida koolitatakse traditsiooniliste masinõppimisalgoritmidega.
See masinõppemeetod vajab traditsiooniliste masinõppealgoritmide asemel palju koolitusproovi, s.t.e., minimaalselt miljoneid sildistatud näiteid. Vastupidi, traditsioonilised masinõppevõtted saavutavad täpse künnise alati, kui suurema treeningvalimi lisamine nende täpsust üldiselt ei paranda. Sügava õppimise klassifikaatorid ületavad parema tulemuse, kui on rohkem andmeid.
18. Gradiendi võimendamise algoritm

Gradiendi suurendamine on masinõppemeetod, mida kasutatakse klassifitseerimiseks ja regressiooniks. See on üks võimsamaid viise ennustava mudeli väljatöötamiseks. Gradiendi suurendamise algoritmil on kolm elementi:
- Kaotuse funktsioon
- Nõrk õppija
- Lisandmudel
19. Hopfieldi võrk
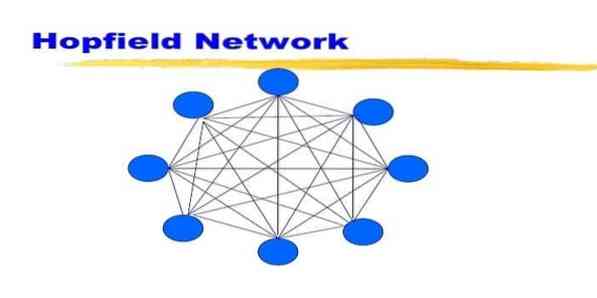
Hopfieldi võrk on üks korduvaid kunstlikke närvivõrke, mille andis John Hopfield 1982. aastal. Selle võrgu eesmärk on salvestada üks või mitu mustrit ja meenutada osalise sisendi põhjal kõiki mustreid. Hopfieldi võrgus on kõik sõlmed nii sisendid kui väljundid ja täielikult ühendatud.
20. C4.5

C4.5 on otsustuspuu, mille leiutas Ross Quinlan. Selle ID3 täiendusversioon. See algoritmiline programm hõlmab mõnda põhijuhtu:
- Kõik loendis olevad proovid kuuluvad sarnasesse kategooriasse. See loob lehesõlme otsustuspuule, öeldes selle kategooria üle otsustamiseks.
- See loob klassi oodatava väärtuse abil puu otsast kõrgema otsusesõlme.
- See loob eeldatava väärtuse abil puu otsast kõrgema otsusesõlme.
Lõpumõtted
Tõhusa masinõppeprojekti väljatöötamiseks on väga oluline kasutada oma andmetel ja domeenil põhinevat õiget algoritmi. Samuti on hädavajalik mõista iga masinõppimisalgoritmi kriitilist erinevust, et lahendada see, kui ma valin kumma."Nagu masinõppimise lähenemisviisi korral on masin või seade õppimisalgoritmi kaudu õppinud. Usun kindlalt, et see artikkel aitab teil algoritmist aru saada. Kui teil on ettepanekuid või päringuid, küsige palun. Jätka lugemist.


