Miks Lucenet vaja on?
Otsing on üks levinumaid toiminguid, mida me mitu korda päevas teeme. See otsing võib toimuda mitmel veebis oleval veebilehel või muusikarakenduses või koodihoidlas või kõigi nende kombinatsioonis. Võib arvata, et lihtne suhteline andmebaas võib ka otsingut toetada. See on õige. Andmebaasid nagu MySQL toetavad täistekstiotsingut. Aga mis saab veebist või muusikarakendusest või koodihoidlast või nende kõigi kombinatsioonist? Andmebaas ei saa neid andmeid oma veergudesse salvestada. Isegi kui see nii läks, võtab nii suure otsingu käivitamine vastuvõetamatult palju aega.
Täistekstiga otsingumootor on võimeline käivitama otsingupäringu korraga miljonil failil. Andmete rakenduses salvestamise kiirus on tänapäeval tohutu. Sellise andmemahuga täistekstiotsingu käivitamine on keeruline ülesanne. Selle põhjuseks on asjaolu, et vajalik teave võib eksisteerida ühes failis miljarditest veebis hoitavatest failidest.
Kuidas Lucene töötab?
Ilmselge küsimus, mis peaks pähe tulema, on see, kuidas on Lucene täisteksti otsingupäringute käivitamisel nii kiire?? Vastus sellele on muidugi selle loodud indeksite abil. Kuid klassikalise indeksi loomise asemel kasutab Lucene seda Pööratud indeksid.
Klassikalises registris kogume iga dokumendi jaoks täieliku loendi sõnadest või terminitest, mida dokument sisaldab. Inverteeritud registrisse salvestame kõigi dokumentide iga sõna jaoks, millise dokumendi ja positsiooni see sõna / termin võib leida. See on kõrgetasemeline algoritm, mis muudab otsingu väga lihtsaks. Mõelge klassikalise indeksi loomise järgmisele näitele:
Dok1 -> "See", "on", "lihtne", "Lucene", "proov", "klassikaline", "tagurpidi", "register"Doc2 -> "Running", "Elasticsearch", "Ubuntu", "Update"
Doc3 -> "RabbitMQ", "Lucene", "Kafka", "", "Spring", "Boot"
Kui kasutame tagurpidi indeksit, on meil järgmised indeksid:
See -> (2, 71)Lucene -> (1, 9), (12,87)
Apache -> (12, 91)
Raamistik -> (32, 11)
Pööratud indekseid on palju lihtsam hooldada. Oletame, et kui me tahame leida Apache'i minu terminites, siis on mul kohe vastused koos pööratud indeksitega, samas kui klassikalise otsingu korral töötatakse täielike dokumentide korral, mida ei pruugi olla võimalik reaalajas käivitada.
Lucene'i töövoog
Enne kui Lucene saab andmeid päriselt otsida, peab ta tegema samme. Visualiseerime need sammud paremaks mõistmiseks:
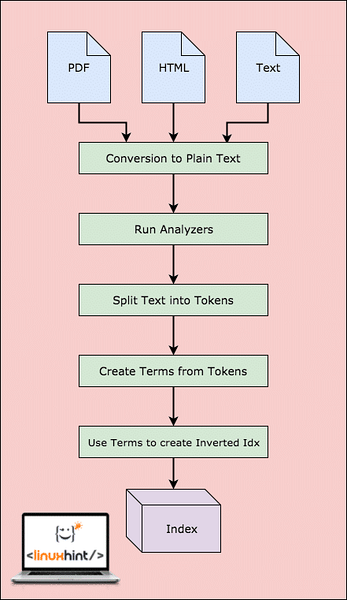
Lucene'i töövoog
Nagu diagrammil näidatud, juhtub Lucene'is nii:
- Lucene'ile antakse dokumente ja muid andmeallikaid
- Iga dokumendi puhul teisendab Lucene need andmed kõigepealt tavaliseks tekstiks ja seejärel Analyzers teisendab selle allika lihttekstiks
- Iga lihttekstis oleva termini jaoks luuakse ümberpööratud indeksid
- Indeksid on otsimiseks valmis
Selle töövooga on Lucene väga tugev täistekstiotsingumootor. Kuid see on ainus osa, mille Lucene täidab. Me peame selle töö ise ära tegema. Vaatame vajalikke indekseerimise komponente.
Lucene komponendid
Selles jaotises kirjeldame indeksite loomiseks kasutatud põhikomponente ja Lucene'i põhiklasse:
- Kataloogid: Lucene indeks salvestab andmeid tavapärastesse failisüsteemi kataloogidesse või mällu, kui vajate suuremat jõudlust. Andmete andmebaasi, RAM-i või ketta salvestamine on täiesti rakenduste valik.
- Dokumendid: Andmed, mida Lucene mootorisse edastame, tuleb teisendada lihttekstiks. Selleks valmistame dokumendiobjekti, mis tähistab seda andmeallikat. Hiljem, kui käivitame otsingupäringu, saame tulemuseks loendi dokumendiobjektidest, mis vastavad edastatud päringule.
- Väljad: Dokumendid on täidetud väljade koguga. Väli on lihtsalt paar (nimi, väärtus) esemed. Niisiis, uue dokumendiobjekti loomisel peame selle täitma sellist tüüpi seotud andmetega. Kui väli on pöördvõrdeliselt indekseeritud, on välja väärtus märgistatud ja saadaval otsimiseks. Kui me kasutame väljad, pole oluline salvestada tegelikku paari, vaid ainult tagurpidi indekseeritud. Nii saame otsustada, millised andmed on ainult otsitavad ja pole olulised salvestamiseks. Vaatame siin ühte näidet:

Välja indekseerimine
Ülalolevas tabelis otsustasime mõned väljad salvestada ja teisi ei salvestata. Kehavälja ei salvestata, vaid see indekseeritakse. See tähendab, et e-kiri tagastatakse selle tulemusena, kui käivitatakse keha sisu ühe tingimuse päring.
- Tingimused: Terminid tähistavad sõna tekstist. Terminid on välja võetud väljade väärtuste analüüsist ja märgistamisest Termin on väikseim üksus, milles otsitakse.
- Analüsaatorid: Analüsaator on indekseerimise ja otsimise protsessi kõige olulisem osa. Analüsaator muudab lihtteksti märkideks ja terminiteks, et neid saaks otsida. Noh, see pole Analüsaatori ainus kohustus. Analüsaator kasutab žetoonide valmistamiseks tokenizerit. Analüsaator teeb ka järgmisi ülesandeid:
- Varjatud: Analüsaator teisendab sõna tüveks. See tähendab, et „lilled” teisendatakse tüvesõnaks „lill”. Niisiis, kui otsitakse sõna „lill”, tagastatakse dokument.
- Filtreerimine: Analüsaator filtreerib ka peatussõnu nagu 'The', 'is' jne. kuna need sõnad ei meelita käivitatavaid päringuid ega ole produktiivsed.
- Normaliseerimine: see protsess eemaldab aktsendid ja muud tähemärgised.
See on lihtsalt StandardAnalyzeri tavaline vastutus.
Näidisrakendus
Näite jaoks näidisprojekti loomiseks kasutame ühte paljudest Maveni arhetüüpidest. Projekti loomiseks käivitage järgmine käsk kataloogis, mida kasutate tööruumina:
mvn arhetüüp: genereeri -DgroupId = com.linuxhint.näide -DartifactId = LH-LuceneExample -DarchetypeArtifactId = maven-archetype-quickstart -DinteractiveMode = falseKui kasutate mavenit esmakordselt, võtab käsu genereerimine mõne sekundi möödumiseks, sest maven peab genereerimistoimingu tegemiseks alla laadima kõik vajalikud pistikprogrammid ja artefaktid. Projekti väljund näeb välja järgmine:
Projekti seadistamine
Kui olete projekti loonud, avage see julgelt oma lemmik-IDE-s. Järgmine samm on lisada projekti sobivad Maven Dependencies. Siin on pom.xml-fail koos sobivate sõltuvustega:
Lõpuks, et mõista kõiki selle sõltuvuse lisamisel projekti lisatud JAR-e, võime käivitada lihtsa Maveni käsu, mis võimaldab meil näha projekti täielikku sõltuvuspuud, kui lisame sellele mõned sõltuvused. Siin on käsk, mida saame kasutada:
mvn sõltuvus: puuSelle käsu käivitamisel näitab see meile järgmist sõltuvuspuud: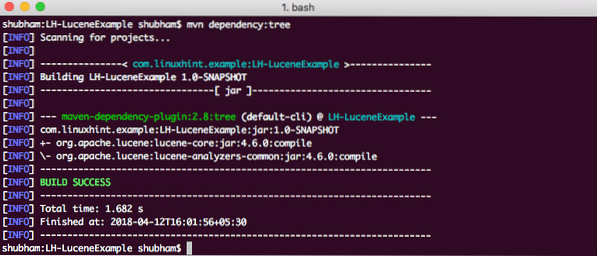
Lõpuks loome klassi SimpleIndexer, mis töötab
import java.io.Fail;
import java.io.FileReader;
import java.io.IOException;
impordi org.apache.lutseen.analüüs.Analüsaator;
impordi org.apache.lutseen.analüüs.standard.StandardAnalyzer;
impordi org.apache.lutseen.dokument.Dokument;
impordi org.apache.lutseen.dokument.StoredField;
impordi org.apache.lutseen.dokument.Tekstiväli;
impordi org.apache.lutseen.indeks.IndexWriter;
impordi org.apache.lutseen.indeks.IndexWriterConfig;
impordi org.apache.lutseen.pood.FSD kataloog;
impordi org.apache.lutseen.kasut.Versioon;
avalik klass SimpleIndexer
privaatne staatiline lõplik String indexDirectory = "/ Kasutajad / shubham / kuskil / LH-LuceneExample / Index";
privaatne staatiline lõplik string String dirToBeIndexed = "/ Kasutajad / shubham / kuskil / LH-LuceneExample / src / main / java / com / linuxhint / example";
public staatiline void main (String [] args) viskab erandi
Fail indexDir = uus fail (indexDirectory);
Fail dataDir = uus fail (dirToBeIndexed);
SimpleIndexeri indekser = uus SimpleIndexer ();
int numIndexed = indekseerija.indeks (indexDir, dataDir);
Süsteem.välja.println ("Indekseeritud faile kokku" + numIndexed);
private int register (File indexDir, File dataDir) viskab IOException
Analüsaatori analüsaator = uus StandardAnalyzer (versioon.LUCENE_46);
IndexWriterConfig config = uus IndexWriterConfig (versioon.LUCENE_46,
analüsaator);
IndexWriter indexWriter = uus IndexWriter (FSDirectory.avatud (indexDir),
konfig)
Fail [] failid = dataDir.listFiles ();
for (fail f: failid)
Süsteem.välja.println ("Indekseerimisfail" + f.getCanonicalPath ());
Dokumendi dokument = uus dokument ();
doc.add (uus TextField ("sisu", uus FileReader (f)));
doc.add (uus StoredField ("failinimi", f.getCanonicalPath ()));
indexWriter.addDocument (doc);
int numIndexed = indexWriter.maxDoc ();
indexWriter.Sulge();
return numIndexed;
Selles koodis tegime just dokumendi eksemplari ja lisasime uue välja, mis tähistab faili sisu. Selle väljundi saame selle faili käivitamisel:
Indekseerimisfail / Kasutajad / shubham / kuskil / LH-LuceneExample / src / main / java / com / linuxhint / example / SimpleIndexer.javaIndekseeritud faile kokku 1
Samuti luuakse projekti sees uus kataloog järgmise sisuga:
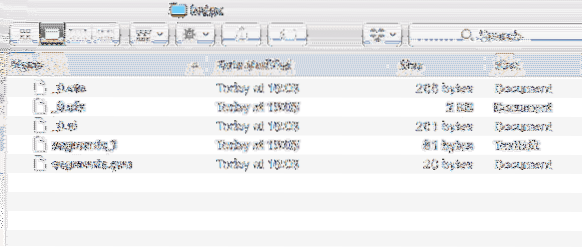
Indeksi andmed
Analüüsime, millised kõik failid selles registris luuakse, veel Lucene'i õppetundides.
Järeldus
Selles tunnis vaatasime, kuidas Apache Lucene töötab, ja tegime ka lihtsa näidisrakenduse, mis põhines Mavenil ja Java-l.


