pip installige BeautifulSoup4
Installimise õnnestumise kontrollimiseks aktiveerige Pythoni interaktiivne kest ja importige BeautifulSoup. Kui viga ei ilmu, tähendab see, et kõik läks hästi. Kui te ei tea, kuidas sellega edasi minna, tippige oma terminali järgmised käsud.
$ pythonPython 3.5.2 (vaikimisi, 14. september 2017, 22:51:06)
[GCC 5.4.0 20160609] Linuxis
Lisateabe saamiseks sisestage "abi", "autoriõigus", "krediit" või "litsents".
>>> import bs4
BeautifulSoupi teegiga töötamiseks peate sisestama HTML-i. Päris veebisaitidega töötades saate taotluste kogu abil saada veebilehe HTML-i. Päringute kogu installimine ja kasutamine ei kuulu selle artikli reguleerimisalasse, kuid võite leida juhiseid dokumentatsioonis, mida on üsna lihtne kasutada. Selle artikli jaoks kasutame lihtsalt HTML-i pythoni stringis, mida me kutsuksime HTML.
html = "" "[meiliga kaitstud]
pparkerworks.com
"" "
Beautifulsoupi kasutamiseks impordime selle koodi alloleva koodi abil:
bs4-st importige BeautifulSoupSee tooks BeautifulSoupi meie nimeruumi ja saame seda kasutada oma stringi sõelumisel.
supp = ilus supp (html, "lxml")Nüüd, supp on bs4 tüüpi objekt BeautifulSoup.Ja saame jõuda kõikidel BeautifulSoupi toimingutel suppmuutuv.
Vaatame mõningaid asju, mida saame nüüd BeautifulSoupiga teha.
KOLEDA, ILUSA TEEMINE
Kui BeautifulSoup parsib html-d, pole see tavaliselt kõige paremas vormingus. Vahed on päris kohutavad. Sildid on raskesti leitavad. Siin on pilt, mis näitab, kuidas nad välja näeksid, kui jõuate printida supp:
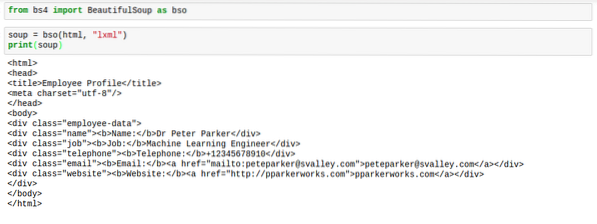
Sellele on aga lahendus. Lahendus annab html-le täiusliku vahemaa, muutes asjad heaks. Seda lahendust nimetatakse vääriliseltilustama".
Tõsi, te ei pruugi seda funktsiooni enamasti kasutada; Siiski võib juhtuda, et teil pole juurdepääsu veebibrauseri kontrollimiselemendile. Sel ajal, kui ressursid on piiratud, võib prettify meetod olla väga kasulik.
Seda saate kasutada järgmiselt
supp.ilustama ()Märgistus näeks korralikult paigutatud, nagu alloleval pildil:
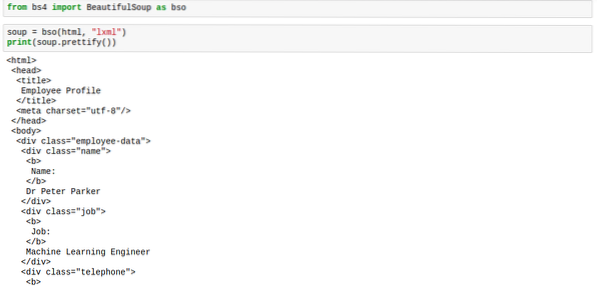
Kui rakendate supile prettify meetodit, pole tulemus enam tüüpi bs4.IlusSupp. Tulemuseks on nüüd tüüp 'unicode'. See tähendab, et te ei saa sellel kasutada muid BeautifulSoupi meetodeid, kuid suppi ennast see ei mõjuta, seega oleme ohutud.
MEIE LEMMIKLISTE MÄRKIDE LEITMINE
HTML koosneb siltidest. See salvestab neisse kõik oma andmed ja kogu selle segaduse keskel peituvad meile vajalikud andmed. Põhimõtteliselt tähendab see, et kui leiame õiged sildid, saame vajaliku kätte.
Niisiis, kuidas leida õiged sildid? Kasutame BeautifulSoupi leidmise ja leidmise_meetodeid.
Nad töötavad järgmiselt:
The leidma meetod otsib esimest vajaliku nimega silti ja tagastab objekti tüüpi bs4.element.Silt.
The leidma kõik meetod seevastu otsib kõiki vajaliku sildi nimega silte ja tagastab need bs4 tüüpi loendina.element.ResultSet. Kõik loendis olevad üksused on tüüpi bs4.element.Märgistage, et saaksime loendis indekseerida ja jätkata oma kaunite suppide uurimist.
Vaatame koodi. Leiame üles kõik div sildid:
supp.leidma („div“)Saaksime järgmise tulemuse:
HTML-muutujat kontrollides märkate, et see on esimene div-silt.
supp.find_all („div“)Saaksime järgmise tulemuse:
[[meiliga kaitstud]
pparkerworks.com
See tagastab loendi. Kui soovite näiteks kolmandat div-märgendit, käivitate järgmise koodi:
supp.find_all ("div") [2]See tagastaks järgmise:
MEIE LEMMIKLISTE MÄRGISTUSTE OMADUSTE LEITAMINE
Nüüd, kui oleme näinud, kuidas oma lemmikmärgendeid hankida, kuidas nende atribuute hankida?
Võib-olla mõtlete sel hetkel: „Milleks me atribuute vajame?". Noh, palju kordi on enamus vajalikest andmetest meiliaadressid ja veebisaidid. Sellised andmed on tavaliselt veebilehtedel hüperlingitud, linkidega on atribuut „href”.
Kui oleme vajaliku sildi välja pakkinud, kasutades meetodit find või find_all, saame rakendades atribuudid meelitab. See tagastaks atribuudi sõnastiku ja selle väärtuse.
Näiteks e-posti atribuudi saamiseks saame sildid, mis ümbritsevad vajalikku teavet, ja tehke järgmist.
supp.find_all („a“) [0].meelitabMis annaks järgmise tulemuse:
'href': 'mailto: [meiliga kaitstud]'Sama asi veebisaidi atribuudi puhul.
supp.find_all („a“) [1].meelitabMis annaks järgmise tulemuse:
'href': 'http: // pparkerworks.com'Tagastatud väärtused on sõnastikud ja võtmete ja väärtuste saamiseks saab rakendada tavalist sõnastiku süntaksit.
NÄEME VANEMAT JA LASTE
Igal pool on silte. Mõnikord tahame teada, mis on laste sildid ja mis on vanem silt.
Kui te ei tea veel, mis on vanema- ja lapsemärgis, peaks sellest lühikesest selgitusest piisama: vanemmärgend on kõnealuse sildi vahetu välimine silt ja laps on selle sisemine silt.
Vaadates meie HTML-i, on body silt kõigi div-siltide vanemmärgend. Samuti on rasvane silt ja ankrumärgend div-siltide lapsed, kui see on asjakohane, kuna kõigil div-siltidel pole ankrusilte.
Seega pääseme vanemamärgendile juurde, helistades aadressile findVanem meetod.
supp.leidma ("div").findParent ()See tagastaks kogu kehamärgendi:
[meiliga kaitstud]
pparkerworks.com
Neljanda div-märgendi laste sildi saamiseks kutsume seda leidaLapsed meetod:
supp.find_all ("div") [4].findLapsed ()See tagastab järgmise:
[Veebisait:, pparkerworks.com]MIS SEDA MEIL ON?
Veebilehti sirvides ei näe me silte kõikjal ekraanil. Kõik, mida me näeme, on erinevate siltide sisu. Mis siis, kui soovime sildi sisu, ilma et kõik nurksulgudes elu ebamugavaks teeks? See pole keeruline, kõik, mida me teeksime, on helistada get_text meetod valitud sildile ja saame teksti märgendisse ning kui märgendis on muid silte, saab see ka nende tekstiväärtused.
Siin on näide:
supp.leidma ("keha").get_text ()See tagastab kõik tekstiväärtused kehamärgendis:
Nimi: dr Peter ParkerTöö: masinaõppeinsener
Telefon: +12345678910
E-post: [meiliga kaitstud]
Veebisait: pparkerworks.com
JÄRELDUS
See on see, mis meil selle artikli jaoks on. Kaunise supiga saab aga teha veel muidki huvitavaid asju. Võite tutvuda dokumentatsiooniga või kasutada dir (BeautfulSoup) interaktiivses kestas, et näha toimingute loendit, mida saab objektil BeautifulSoup teha. See on kõik minult täna, kuni ma uuesti kirjutan.


